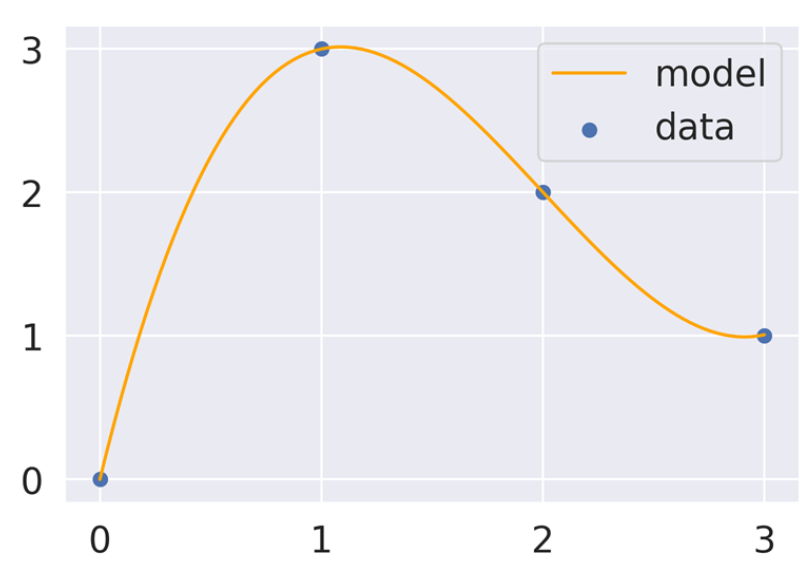
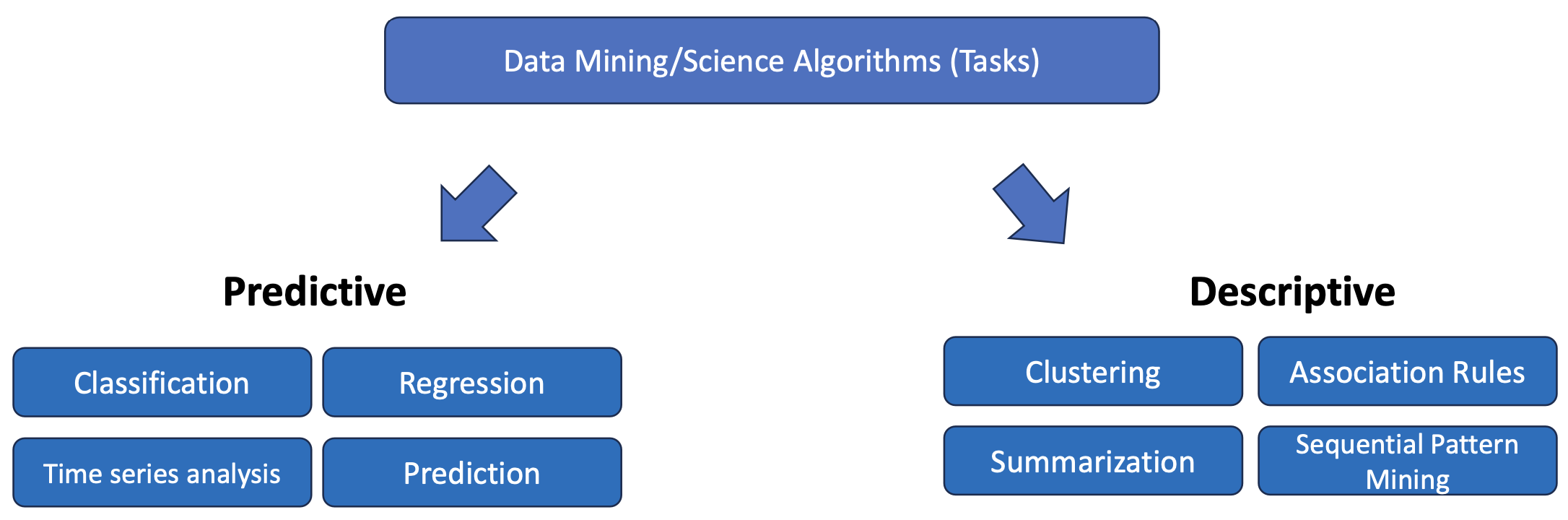
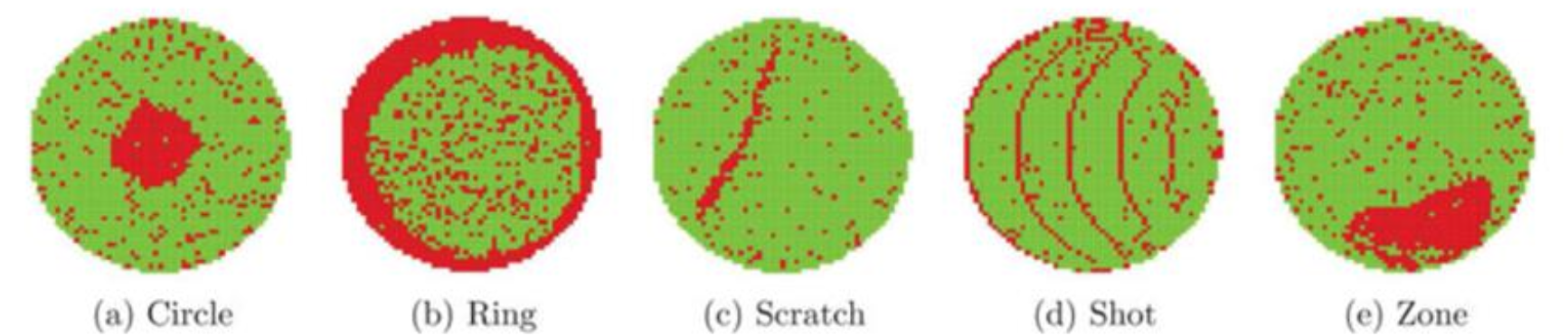
Feature EngineeringFeature Engineering은 전통적인 머신 러닝 기법에서 굉장히 중요한 작업이다. 이러한 feature를 고려해야 한다는 것은 일종의 바이어스에 기반한 분석이기 때문에 Feature Engineering을 사용하지 않아도 되는 딥러닝이 굉장히 powerful하다. 그럼에도 불구하고 전통적인 머신러닝의 기법을 사용해야 할 때가 있다. 예를 들어 데이터가 충분하지 않거나, 존재하는 기법으로도 분석이 잘 되는 경우에는 굳이 딥러닝을 사용할 필요가 없기 때문이다. One hot encoding An Alternate Approach Higher-order Polynomial Exampledegree를 높임으로써 오류를 줄일 수 있다.Overfitting차수를 높여 무작..