Feature Engineering
Feature Engineering은 전통적인 머신 러닝 기법에서 굉장히 중요한 작업이다. 이러한 feature를 고려해야 한다는 것은 일종의 바이어스에 기반한 분석이기 때문에 Feature Engineering을 사용하지 않아도 되는 딥러닝이 굉장히 powerful하다.
그럼에도 불구하고 전통적인 머신러닝의 기법을 사용해야 할 때가 있다. 예를 들어 데이터가 충분하지 않거나, 존재하는 기법으로도 분석이 잘 되는 경우에는 굳이 딥러닝을 사용할 필요가 없기 때문이다.
One hot encoding
An Alternate Approach
Higher-order Polynomial Example
degree를 높임으로써 오류를 줄일 수 있다.
Overfitting
차수를 높여 무작정 오류를 줄이면 overfitting이라는 문제가 발생할 수 있다.
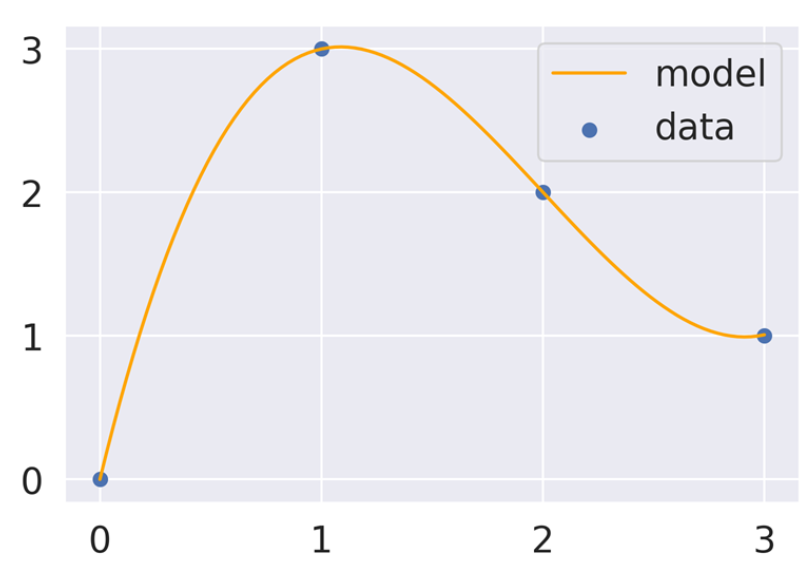
극단적인 예시를 하나 들어보자. 데이터가 4개가 존재했을 때, 우리는 각 점을 모두 지나기 위해

위와 같은 식을 세웠다고 생각해보자. 그런데 우리가 만약 100개의 feature가 입력으로 들어왔을 때, 우리는 100개의 데이터 포인트를 만들어 파라미터의 개수를 100개로 모델을 fitting할 수 있다. 그런데 이러한 경우 MSE는 항상 0이 되고, 우리가 overfitting되었다고 하며, useless하다.
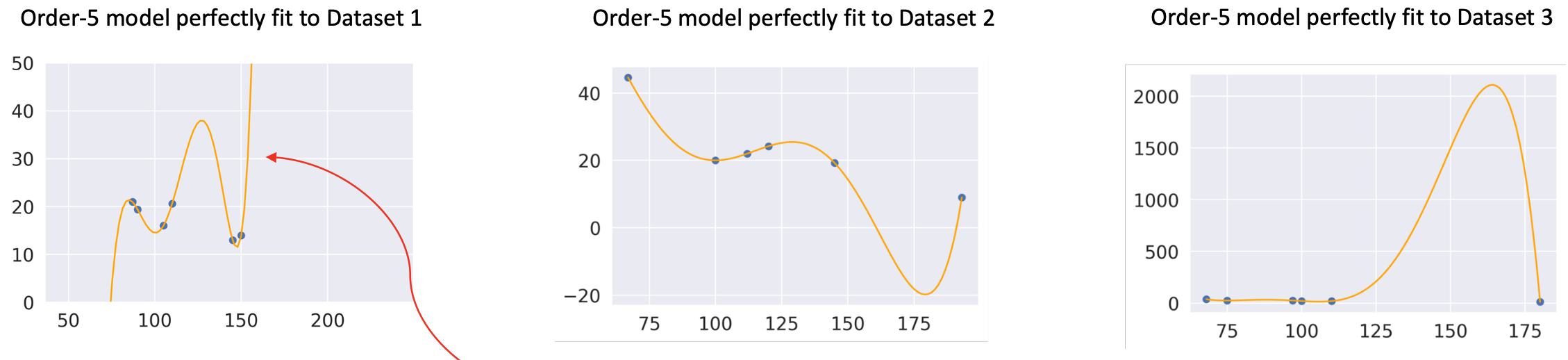
위 사진은 자동차의 연비와 관련한 데이터 셋에서 무작위로 6개의 데이터를 뽑아 해당 데이터에 대해 완벽하게 맞는 모델을 위와 같이 제작했다고 하자.

그런데, 위와 같은 모델은 unseen 데이터를 넣었을 때 제대로된 결과를 출력하지 않고 트레이닝 데이터에 대해서만 잘 표현하고 있음을 확인할 수 있다.
Variance and Training Error

즉, degree가 높아질 수록 위 사진과 같이 regression 선의 변화가 심해지는 것을 확인할 수 있는데, degree가 높아질 수록 MSE도 낮아지고 있음을 확인할 수 있다.

따라서 우리는 모델의 complex degree가 올라가면, training error은 줄어든다고 할 수 있다.

위 사진은 동일한 데이터 셋으로부터 각각 subset을 뽑아 모델을 fitting한 모습이다. 이때, 위 두 개의 모습은 order 2, 즉 x^2까지 고려한 ploynomial로 그린 형태이고, 아래 두 개의 모습은 order 6, 즉 x^6까지 고려한 polynimial로 그린 형태이다.
이때, x^2까지 고려했을 때, 샘플데이터가 조금 달라도 전체적인 모양은 비슷하다. 그러나 x^6까지 고려한 아래의 경우 샘플데이터가 달라지면 모델의 전체적인 모양이 달라지고 있음을 확인할 수 있다. 이를 우리는 모델 varience라고 한다. 따라서 consist하게 계산되지 않는 문제가 있다.

즉, 모델의 complexity가 높을 수록 overfitting하기 쉽고, 이는 모델의 variance가 커짐을 의미한다. 그렇다면, degree를 높이는 것이 나쁘다고 판단하여 낮춰버리면, training error를 줄일 수 없어서 그 중간의 sweet spot를 찾아야 한다.
Attribute(Feature) Selection
우리는 전체 데이터 feature 혹은 attribute 중에서 redundant한 정보를 없애고, 필요한 요소만 minimun하게 뽑는 것을 Attribute(Feature) Selection라고 한다.
Attribute Creation
'Computer Science > 데이터 과학(Data Science)' 카테고리의 다른 글
| [데과/DS] Data Preprocessing (0) | 2024.04.30 |
|---|---|
| [데과/DS] Visualization Theory (0) | 2024.04.29 |
| [데과/DS] Data Understanding & Visualization (0) | 2024.04.29 |
| [데과/DS] Regular Expression (정규 표현식) (1) | 2024.04.28 |
| [데과/DS] Data Acquisition (데이터 취득) (0) | 2024.04.28 |