본 포스트는 2024년 봄 학기 충남대학교 이종률 교수님의 데이터 과학 강의 정리자료입니다.
Regular Expression (정규 표현식)
어떤 low level의 텍스트가 있을 때 일종의 정해진 패턴을 매치하는 sequence character이다. 이러한 패턴을 정의하는 스타일은 여러 가지 존재한다.
RE: /h[aeiou]+/g
위와 같은 정규표현식이 있다고 가정해보자. 위의 정규표현식이 나타내고 있는 것은 h로 시작하는 문자열을 찾는 것인데, 이때 [aeiou], 즉 모음을 +를 통해 1개 이상 찾고 있음을 확인할 수 있다. 이때, 가장 뒤의 g는 전역적으로, global하게 문자열을 찾고 있음을 의미한다. 이때 /를 이용하여 정규표현식의 시작과 끝을 나타내고 있다.

따라서 앞의 정규표현식으로 찾은 문자열의 결과는 위 사진과 같다.

위 사진에서 RE는 가장 하위의 언어로 굉장히 powerful하다는 특징을 가지고 있다. 또 이해하게 되면 굉장히 재미있는 언어라고 한다. 오래된 language이기 때문에 compact하게 정리가 잘 되어 있다.
RE의 경우 구조적인 parsing을 진행하는 것이 아니기 때문에 RE를 통해 구조적으로 이해하는 것은 어렵다. 그러나 최근에 툴의 개발로 환경에 따라 구조를 일부 이해하는 것이 가능하다고 한다.

RE의 quick guide는 위 사진과 같다. 이제 차례로 정규표현식을 사용하는 방법에 대해 알아보자.
1. 프로그램에서 정규표현식을 사용하기 전 "import re"를 통해 라이브러리를 불러온다.
2. 문자열에서 사용할 수 있는 find()와 같은 역할을 하는 메소드로, 정규표현식을 통해 문자열을 찾는 re.search() 메소드를 사용한다.
3. re.findall()을 사용하여 정규표현식과 일치하는 문자열 부분을 추출할 수 있다. 이 메소드는 find()와 arr[5:10]과 같은 슬라이싱을 합한 것과 비슷하다. 즉, 매칭되는 모든 문자열을 반환한다.

위 사진에서 왼쪽은 find()를 사용한 모습, 오른쪽은 re.search()를 사용한 모습이다. 이때 rstrip()는 문자열의 오른쪽에 존재하는 whitespace(공백)을 제거해주는 함수이다.
이때, string이 매치가 되는 것을 확인하고 싶으면 search, string을 직접 찾고 싶으면 find, 해당하는 경우를 모두 찾으려면 findall을 사용하면 된다. 정규표현식을 사용하고 싶지 않다면, 위 사진에서 오른쪽과 같이 코드를 구성하면 된다.

위 사진도 동일한 예시지만, startswith를 통해 해당 문자열로 시작하는 line을 찾고자함을 알 수 있다. 이때, startswith()는 정규표현식 앞에 ^을 붙여줌으로써 동일한 결과를 얻을 수 있다.
그런데, 우리는 앞서 RE를 표현하기 위해 '/'를 사용한다고 언급하였는데, 파이썬의 경우 /를 사용하지 않아도 된다고 한다.
Wild-Card Characters
dot(.) 문자는 RE에서 어떤 문자와도 매칭이 가능하다. 또한 어떤 문자를 여러 번 매칭할 때는 asterisk(*) 문자를 통해서 나타낼 수 있다. 따라서 X로 시작하는 문자열을 찾고 싶은 경우 정규표현식은 아래와 같다.
^X.*:
^을 통해 X로 시작하는 문자열을 찾고 있음을 나타낼 수 있고, .과 *을 통해 어떤 문자(.)를 0개 이상(*) 매칭되도록 하는데, 그 매칭은 :이 뒤에 존재하는 경우를 말한다.
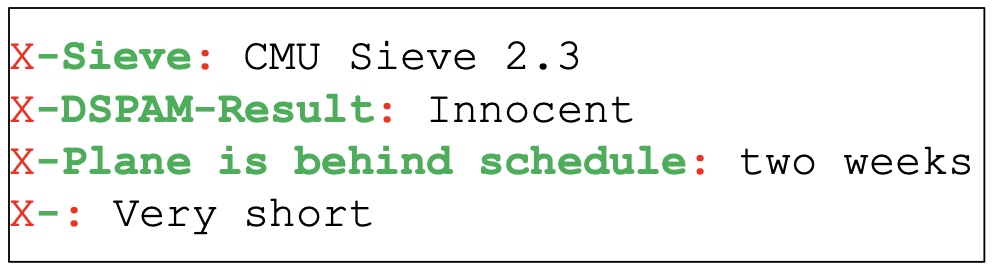
따라서 위의 정규표현식에 매칭되는 문자열은 위 사진과 같다. 이때, 위 사진에서 볼 수 있듯이 : 이후의 문자열과는 매칭되지 않고 있음을 볼 수 있다. 정규표현식을 통해 :까지 매칭하라고 표기되어 있기 때문이다.
^X-\S+:
위의 정규표현식에서 추가적으로 조건을 설정할 수 있다. 위 정규표현식은 X-로 시작하고, \S를 통해 공백이 아닌 문자가 1개 이상(+) 존재하며, : 으로 끝나는 문자열을 찾고 있다고 해석할 수 있다.

따라서 위 사진과 같은 결과값을 가질 수 있다. 세 번째 문자열의 경우 X-와 : 사이에 공백이 존재하기 때문에 해당 RE에 포함이 되지 않으며, 네 번째 문자열의 경우 X-와 : 사이에 어떠한 공백이 아닌 문자가 없기 때문에 포함되지 않는다.
Matching and Extracting Data
re.search() 함수의 경우 문자열에 대해 해당 정규표현식의 존재 여부인 T/F만 반환한다. 따라서 우리는 정규표현식에 대응하는 모든 문자열을 찾기 위해 re.findall() 함수를 사용할 수 있다.

findall()을 사용하는 예시는 위 사진과 같은데, 위 사진에서 사용한 [0-9]+는 모든 digit, 즉 0부터 9까지의 모든 숫자를 1개 이상 매칭하겠다는 의미이다.
이때 특이사항으로는 정규표현식은 문자열이기 때문에 위와 같이 숫자로 결과값을 뽑아낸다고 하더라도, 뽑힌 결과는 문자열(string) 형태이다. 따라서 해당 결과값을 사용하고 싶다면 int형으로 형변환을 진행해야 한다.

또 다른 예시로는 위 사진에서 [AEIOU]를 찾고 있지만, 각 모음에 대해 문자열에서 대문자로 존재하는 부분이 없기 때문에 아무것도 매칭되지 않아 빈 배열을 return하고 있음을 확인할 수 있다.
Warning: Greedy Matching


^F.+:이라는 정규식을 사용했을 때, 결과는 위 사진과 같다. 우리는 "From:"까지만 찾고 싶은데 From: 뒤에 또 다른 콜론이 있는 경우 위 사진과 같이 모든 문자열을 다 찾아버리는 것이다.

이는 *과 +가 매칭이 가능한 최대의 경우(greedy)를 찾으려고 하기 때문이다. 따라서 ^F.+?:와 같이 정규표현식에 ?를 추가해주면 not greedy하게 원하는 문자열을 찾을 수 있다.

만약 From: ---- : ---- :와 같은 문자열이 있다고 했을 때, 두 번째 콜론(:)까지 매칭하고 싶은 경우도 있을 것이다. 이 경우에는 ?로 매칭될 수 없고, 별도의 패턴을 사용하거나, 원하는 콜론의 개수까지 직접 표기해주는 방법밖에 없다.
Fine-Tuning String Extraction

어떤 meta 데이터가 한 줄이 있을 때, 이메일 주소를 추출하고 싶은 경우 우리는 @ 기호를 기준으로 앞뒤로 non-whitespace 문자를 뽑아오면 된다.


위와 같은 정규식을 사용했을 때의 결과 모습이다.

그런데, 이와 같이 이메일 주소를 추출할 수 있지만, 매칭을 정확하게 시키는 것이 어려울 때가 있다. 위의 예시에서 "From" 다음에 이메일 주소가 오기 때문에 정규표현식을 위와 같이 작성하여 () (괄호)를 통해 추출하고자하는 문자열의 구역을 정해줄 수 있다.

따라서 위 정규표현식을 통해 매칭되는 결과는 위 사진과 같은데, 파란색 부분이 실제로 매칭되는 부분이지만, 빨간색 부분이 실제로 추출되는 부분임을 알 수 있다.
String Parsing Example
앞선 예제에서 만약 host 부분만 추출하고 싶은 경우이다.

위 사진의 경우 @의 위치를 찾고, @ 이후에 존재하는 whitespace를 찾은 후 그 사이에 존재하는 문자열을 추출하는 방법이다. 그런데 위와 같이 코드를 작성하면, 번거로울 뿐만 아니라 가독성도 떨어진다는 단점이 존재한다.

물론 우리가 항상 정규표현식을 사용하는 것은 아니다. 위 사진처럼 공백을 기준으로 split를 진행한 후, 배열의 두 번째 요소가 이메일이기 때문에 1번 인덱스의 값에서 @를 기준으로 또 다시 split하고, 또 두 번째 요소의 값을 가져오면 쉽게 host 주소를 가져올 수 있다.

그러나 위와 같은 정규표현식을 사용하면 한 줄로 간단하게 원하는 부분을 추출해낼 수 있다. 위 정규표현식은 @ 이후 () 내부에 존재하는 부분만 추출하겠다는 의미를 가지고 있으며, [^ ]를 통해 스페이스 부분을 제외한 문자(non-blank)를 *을 통해 0개 이상 찾고 있음을 알 수 있다.
이때, \S를 사용하지 않고 [^ ]를 사용하는 이유는, \S에는 \t, \n과 같이 스페이스가 아닌 공백문자가 존재할 수 있기 때문에 [^ ]를 통해 스페이스 하나만 구분해낼 수 있다.

위 정규표현식을 사용한 결과이다.

From으로 시작하는 문자열인 경우 위와 같이도 나타낼 수 있다.
More Example

만약 위와 같이 메일의 spam confidence를 위와 같이 나타내고 있다고 했을 때, 우리는 confidence value의 최대값을 찾기 위해 아래와 같이 코드를 구성할 수 있다.

이때, 정규표현식의 [0-9.]+의 의미는 소수점을 의미하는 것으로 0-9의 정수 또는 점(.)을 1개 이상 매칭하겠다는 의미이다.

위 코드의 결과값이다.
Escape Character ( \ )
앞선 RE의 quick guide에서 ^는 문장의 시작, $는 문장의 끝을 의미한다고 짧게 언급하였다. 그러나, 우리가 ^나 $을 정규표현식의 기호가 아닌, 문자 하나로 사용하고 싶을 때에는 escape 문자인 '\'을 사용할 수 있다.

따라서 위 사진과 같이 정규표현식을 '\$[0-9.]+'라고 작성하는 경우 $를 문자로 인식할 수 있다. 이때, \\ 처럼 역슬래시를 두 번 작성하면 마찬가지로 \을 문자 하나로 인식하게 만들 수 있다.
'Computer Science > 데이터 과학(Data Science)' 카테고리의 다른 글
| [데과/DS] Visualization Theory (0) | 2024.04.29 |
|---|---|
| [데과/DS] Data Understanding & Visualization (0) | 2024.04.29 |
| [데과/DS] Data Acquisition (데이터 취득) (0) | 2024.04.28 |
| [데과/DS] Data Mining/Science Algorithms (1) | 2024.04.28 |
| [데과/DS] Data Science Methdology (0) | 2024.04.26 |