[진저비어] 2024 하계 모각코 계획 - 1주차토익 공부 및 졸업 프로젝트 진행사항 파악 - 2주차토익 공부 및 졸업 프로젝트 밀린 사항 진행 - 3주차토익 공부 및 졸업 프로젝트에 적용할 수 있는 다양한 기술 논문 찾아보기 - 4주차토익 공부 및 졸업 프로젝트에 적용할 수 있는 다양한 기술 논문 찾아보기 - 5주차토익 공부 및 졸업 프로젝트에 적용할 수 있는 다양한 기술 코드 적용해보기 - 6주차토익 공부 및 졸업 프로젝트에 적용할 수 있는 다양한 기술 코드 적용해보기 모각코/2024 여름 모각코 2024.06.24
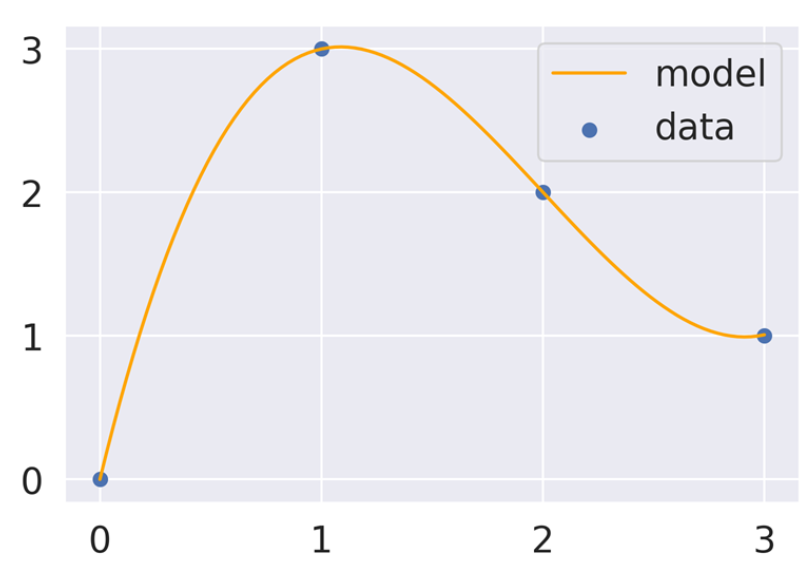
[데과/DS] Feature Engineering Feature EngineeringFeature Engineering은 전통적인 머신 러닝 기법에서 굉장히 중요한 작업이다. 이러한 feature를 고려해야 한다는 것은 일종의 바이어스에 기반한 분석이기 때문에 Feature Engineering을 사용하지 않아도 되는 딥러닝이 굉장히 powerful하다. 그럼에도 불구하고 전통적인 머신러닝의 기법을 사용해야 할 때가 있다. 예를 들어 데이터가 충분하지 않거나, 존재하는 기법으로도 분석이 잘 되는 경우에는 굳이 딥러닝을 사용할 필요가 없기 때문이다. One hot encoding An Alternate Approach Higher-order Polynomial Exampledegree를 높임으로써 오류를 줄일 수 있다.Overfitting차수를 높여 무작.. Computer Science/데이터 과학(Data Science) 2024.04.30
[데과/DS] Data Preprocessing 본 포스트는 2024년 봄 학기 충남대학교 이종률 교수님의 데이터 과학 강의 정리자료입니다. Data Preprocessing데이터 전처리가 필요한 이유는 현실 세계에 존재하는 데이터를 바로 가져다 쓰기엔 결함이 많기 때문이다. 결함의 종류에 대해 알아보자. imcomplete어떤 속성값이 부족한 경우가 존재한다. noisy오류나 outlier값을 가진 경우가 존재한다. 예를 들어 급여 항목에 음수값이 들어가 있는 경우이다. inconsistent코드나 이름에 일치되지 않는 값이 존재한다. 예를 들어 어떤 rank에 대해 A, B, C로 표기했던 것을 1, 2, 3으로 바꿔 표시한 경우도 해당된다. 데이터가 중복되거나 누락되는 경우 부정확하거나 오해의 소지가 있는 통계 결과는 낼 수 있다. 따라서 데이터.. Computer Science/데이터 과학(Data Science) 2024.04.30
[데과/DS] Visualization Theory 본 포스트는 2024년 봄 학기 충남대학교 이종률 교수님의 데이터 과학 강의 정리자료입니다. Visualization Theory데이터를 시각화하는 목적은 데이터의 결과 혹은 어떤 결론을 남에게 공유하기 위함이다.그러나 위 사진과 같이 데이터의 포인트가 한 곳에 몰려 있으면 가독성이 떨어지기 때문에 Linearization을 진행할 수 있다. Linearization우리는 Linearization을 위해 스케일을 잘 선택해야 한다고 앞에서 언급한 적이 있었다. 이는 Linearization을 한다는 것에 조금 더 의미가 있다. 즉, 우리는 위 그래프와 같이 각 데이터 포인트들이 몰려 있는 형태가 아닌, 어떤 환경일 때 Linear한 relationship가 나오는지 확인하는 것이 중요하다. 따라서 우리는.. Computer Science/데이터 과학(Data Science) 2024.04.29
[데과/DS] Data Understanding & Visualization Data Understanding데이터를 모델링하기 전 데이터의 퀄리티 관점에서 충분한지 판단을 해야 한다. 판단 기준은 아래와 같다. Conpleteness수집된 데이터의 크기나 범위를 말한다. Data Visualization Distribution각 변수가 어떤 frequency로 나타나는지를 표현하는 것을 distribution이라고 한다. 이때 모든 값이 나올 빈도를 모두 더했을 때 100%가 되어야 하며, 우리가 관찰하는 데이터의 수와 같아야 한다.위 데이터가 분포를 잘 보여주고 있는가라고 묻는다면 답은 아니오이다. 위 차트는 60대 이상의 사람을 대상으로 10년 전과 비교하여 여가 시간의 변화량 보여주고 있다. 이때, 위와 같은 차트는 하나의 개인이 여러 개의 카테고리에 속할 수 있을 뿐만.. Computer Science/데이터 과학(Data Science) 2024.04.29
[데과/DS] Regular Expression (정규 표현식) 본 포스트는 2024년 봄 학기 충남대학교 이종률 교수님의 데이터 과학 강의 정리자료입니다. Regular Expression (정규 표현식)어떤 low level의 텍스트가 있을 때 일종의 정해진 패턴을 매치하는 sequence character이다. 이러한 패턴을 정의하는 스타일은 여러 가지 존재한다. RE: /h[aeiou]+/g위와 같은 정규표현식이 있다고 가정해보자. 위의 정규표현식이 나타내고 있는 것은 h로 시작하는 문자열을 찾는 것인데, 이때 [aeiou], 즉 모음을 +를 통해 1개 이상 찾고 있음을 확인할 수 있다. 이때, 가장 뒤의 g는 전역적으로, global하게 문자열을 찾고 있음을 의미한다. 이때 /를 이용하여 정규표현식의 시작과 끝을 나타내고 있다. 따라서 앞의 정규표현식으로 찾.. Computer Science/데이터 과학(Data Science) 2024.04.28
[데과/DS] Data Acquisition (데이터 취득) Data AcquisitionMeaning Data Type Where to get data How to get data Computer Science/데이터 과학(Data Science) 2024.04.28
[데과/DS] Data Mining/Science Algorithms 본 포스트는 2024년 봄 학기 충남대학교 이종률 교수님의 데이터 과학 강의 정리자료입니다. 데이터 마이닝과 데이터 과학 알고리즘은 위 사진과 같이 두 가지의 task로 나눌 수 있다. Predictive어떤 입력으로부터 unseen 데이터, 즉 label이 없는 데이터에 대해 예측을 하는 task이다. 기계학습 관점으로는 supervised learning와 가깝다. Descriptive데이터를 다른 task에 활용할 수 있도록 데이터가 가지고 있는 속성, struct 또는 semantic 등을 추출하는 task이다. 기계학습 관점으로는 unsupervised learning와 가깝다. Classification Clustering Association Rule Mining Regressionregr.. Computer Science/데이터 과학(Data Science) 2024.04.28
[데과/DS] Data Science Methdology 본 포스트는 2024년 봄 학기 충남대학교 이종률 교수님의 데이터 과학 강의 정리자료입니다. Data Science Lifecycle위 사진은 데이터 과학의 생명 주기를 그래프로 나타낸 모습으로 일종의 방법론으로 볼 수 있다. 기본적으로 두 개의 entry point가 있다. 1. Question/Problem Formulation (질문/문제 공식화)우리는 무엇을 알고 싶은지, 어떤 문제를 해결하고 싶어하는지 등에 대한 문제를 정의해야 한다. 또한 어떤 가설을 테스트하는지, 어떤 지표(metircs)를 사용해야 하는지를 정의해야 한다. 2. Data Acquisition and Cleaning (데이터 수집 및 정리)이 단계에서는 우리가 어떤 데이터를 가지고 있고, 어떤 데이터가 부족한지에 대해 판단한.. Computer Science/데이터 과학(Data Science) 2024.04.26
[데과/DS] Introduction to Data Science 본 포스트는 2024년 봄 학기 충남대학교 이종률 교수님의 데이터 과학 강의 정리자료입니다. 데이터 과학 적용 예시Silicon wafer Defect실리콘 웨이퍼의 결함을 탐지할 수 있다. 위 사진처럼 다양한 종류의 결함이 존재하고, 실리콘 웨이퍼의 결함을 탐지함으로써 시설을 정비할 수 있다. 이러한 detection을 데이터 과학을 통해 진행할 수 있다. Item recommendation넷플릭스나 유튜브와 같이 유저에게 컨텐츠를 추천할 때에도 데이터 과학을 사용할 수 있다.위 사진은 product에 따른 인기도를 그래프화한 것이다. 대부분의 product들이 일반적인 인기도를 가지고 있지 않다. 이러한 product들을 long tail이라고 하는데, 추천 시스템의 목표는 사용자의 취향에 맞는 lo.. Computer Science/데이터 과학(Data Science) 2024.04.25