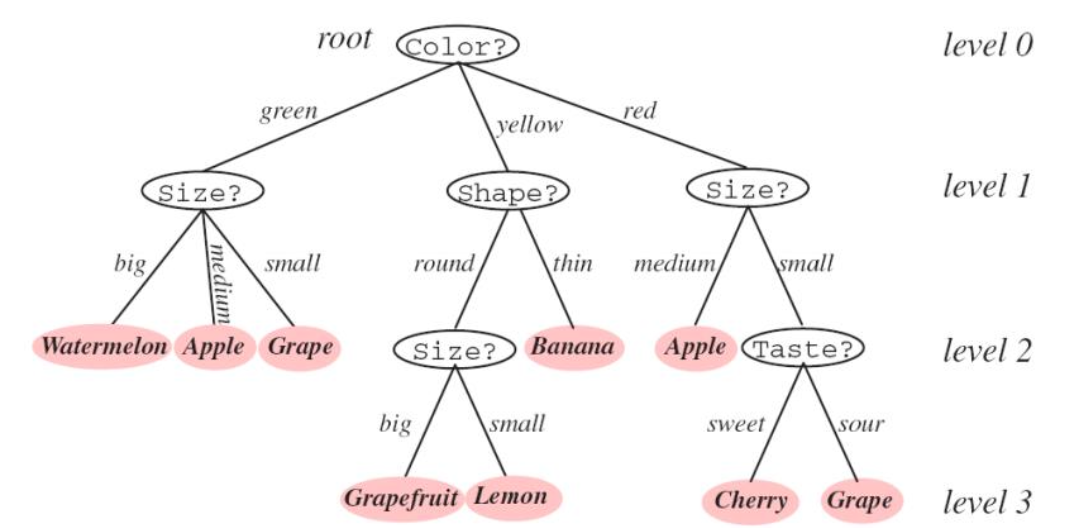
[기계학습/ML] Ensemble Method
Bias-variance dilemma 어떤 하나의 문제를 풀이할 때 여러 가지 모델을 사용할 수 있다. 여러 가지 모델을 사용할 때 기본적으로 트레이닝 데이터를 핸덤하게 추출하여, 각 모델을 학습시킬 수 있다. 즉, 1,000개의 데이터에서 랜덤하게 300개의 데이터를 추출하여 하나의 모델을 만들고, 또 랜덤하게 300개의 데이터를 추출하여 두 번째 모델을 만드는 랜덤한 샘플링을 해주면 작은 데이터를 보지만 더 많은 모델을 만들어 줄 수 있다. 어떤 데이터가 선택되느냐에 따라 다른 모델이 학습이 되는데, 이러한 관점으로 deterministic한(결정적인) 알고리즘이 아니라, Stochastic한(확률적인) 알고리즘의 형태를 띨 수 있다. - Bias 실제값과 예상값의 차이로 아래의 식으로 나타낼 수 ..