Decision Tree
introduction
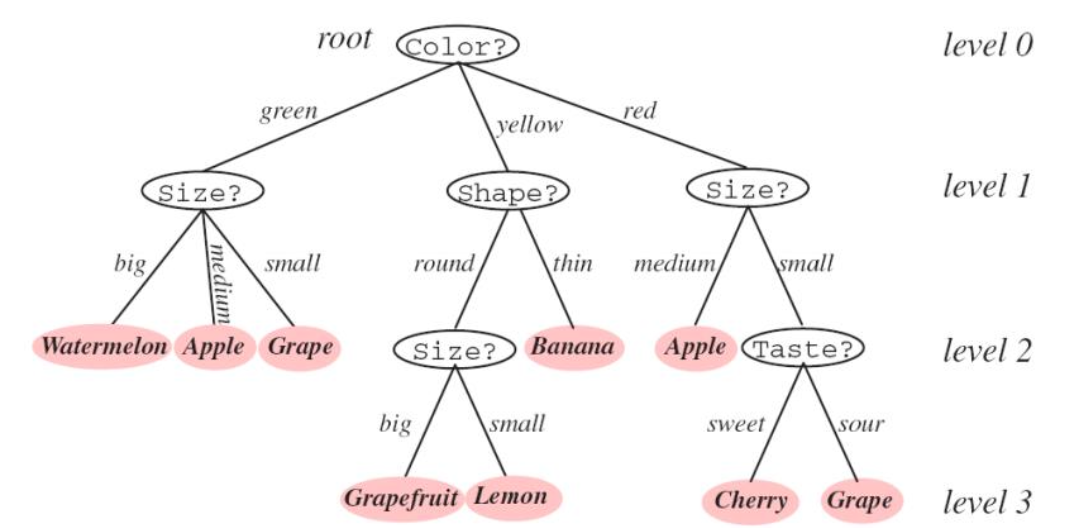
Decision Tree는 나무 결정 트리, 또는 DT라고 한다.
어떤 결정 분류 문제에서 분류에 대한 결정을 내리기 위해 나무 모양에서 계속해서 분기를 진행한다.
가장 쉽게 분류를 할 수 있는 방법은 if문이다.
일반적인 프로그램에서는 if문의 조건을 프로그래머가 설정해주지만,
DT는 데이터에 대한 feature를 계산하며 조건을 학습한다.
프로그램과 DT의 차이점은 위와 같다. 하지만 기본적으로는 IF-THEN 규칙을 적용한다고 생각하면 된다.
DT의 특징
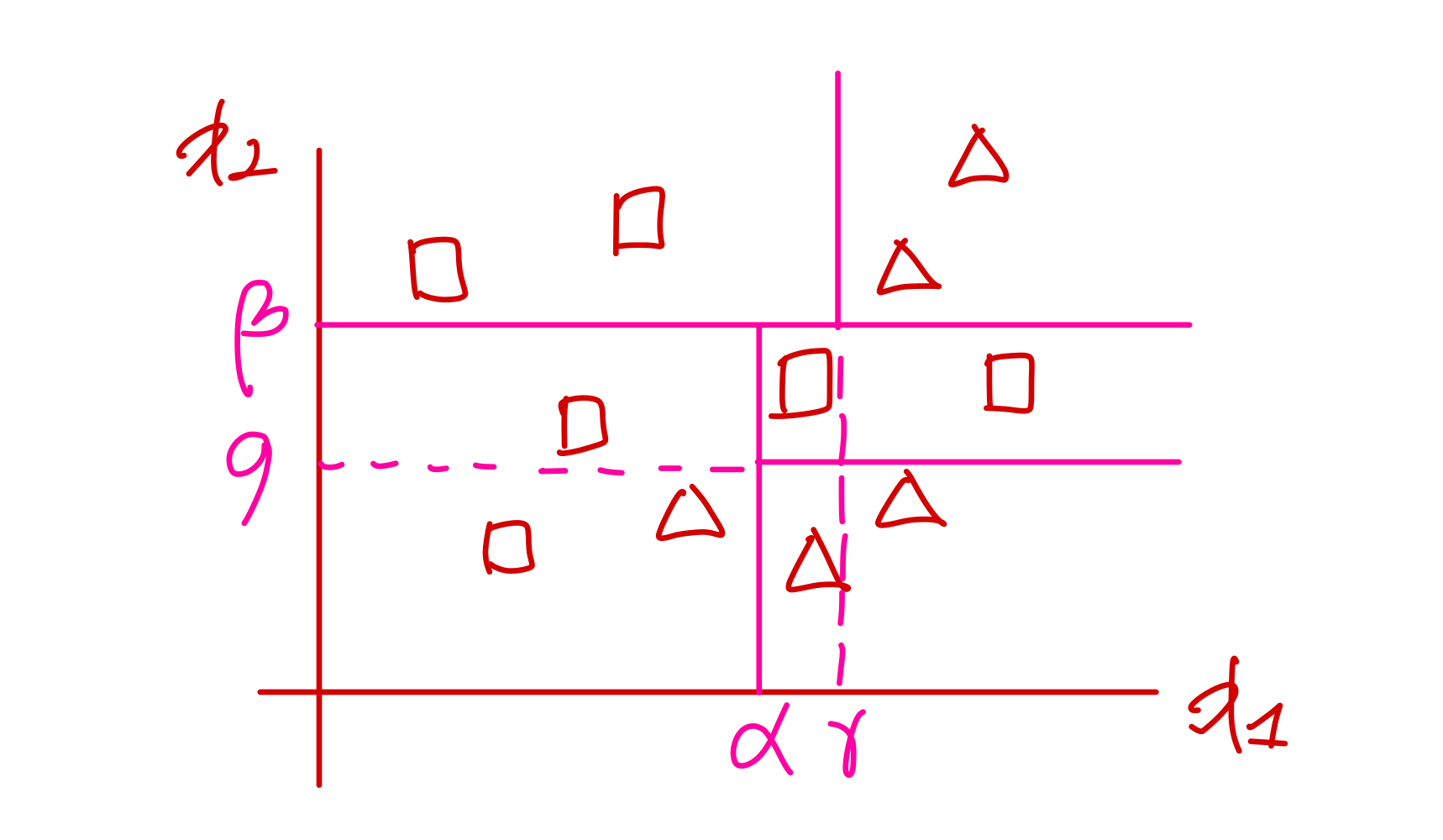
- Recursive partitioning
위 사진과 같이 반복적으로 partitioning을 수행한다.
각 feature에 대해 조건을 설정하고 해당 조건을 충족하면 x1, 충족하지 않으면 x2라고 분류한다.
이러한 파니셔닝이 분류가 잘 될 때까지 계속해서 수행되고, 기준을 만들어 트리의 크기를 키울 수 있다.
- Explicit rule extraction
우리는 머신러닝의 어떤 모델을 사용하여 분류를 했을 때, 어떤 기준에 의해 결과가 분류된지 알 수 없다. 그러나 DT를 사용하면, 위 사진과 같이 알파나 베타와 같은 기준이 되는 값을 명시할 수 있다.
- Interpretability (해석 가능성)
결과를 해석할 수 있다.
- Axis-orthogonal partitioning
위 사진과 같이 기준을 통해 분류할 때 어떤 축에 대해 orthogonal하게(직각으로) 파티셔닝을 시행한다.
- Greedy method
그리디 알고리즘을 사용하는데, 그리디 알고리즘을 번역하면 탐욕 알고리즘이 된다.
데이터가 있을 때 분류를 하기 위한 기준을 세우기 위해서는 현재 데이터를 두 그룹으로 나눴을 때 가장 잘 분류가 되는 기준을 선택한다.
- Robust to nominal variables outliers, missing values
이상값 또는 결측값에 강하다.
- Variable selection
기준에 따라 DT를 생성하면 첫 분기로 feature의 중요도를 파악할 수 있다.
반대로 feature의 중요도에 따라 분기하는 시점을 결정해 줄 수 도 있다.
Terminologies(용어)
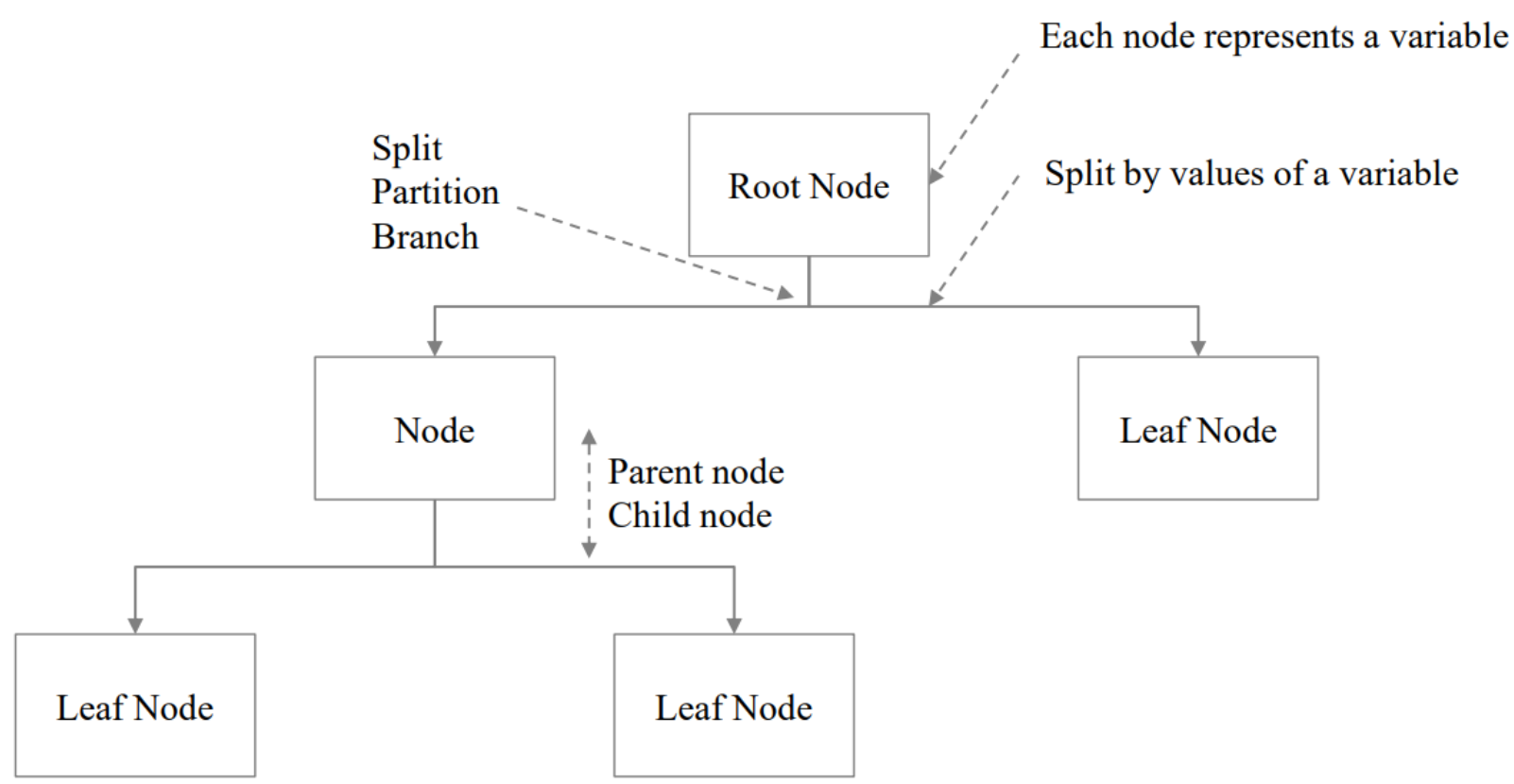
가장 위의 노드를 root node라고 한다.
그 밑에 중간 노드가 존재하고, 최종적으로 어떤 분류가 된 모드를 Leaf node라고 한다.
루트 노드에서 데이터를 어떤 기준으로 나눌 것인지 결정을 해야 한다.
이때, 이렇게 나누는 것을 split한다. 또는 branch를 준다고 한다. 따라서 변수에 대한 어떤 값에 따라 split을 한다.
이렇게, 분류 기준을 계속해서 생성하고 분기하여 최종 노드인 leaf node에 도달하게 된다.
이때, leaf node가 얼마나 분류가 잘 되어 있는가를 판단할 때
leaf node에 얼마나 여러 가지 클래스가 섞여있는지를 판단하는 불순도를 측정한다.
불순도 측정을 통해 모델이 얼마나 잘 분류해주는지를 계산하고, 결과값을 기준으로 분기를 더 생성할지 말지 결정을 해준다.
Example
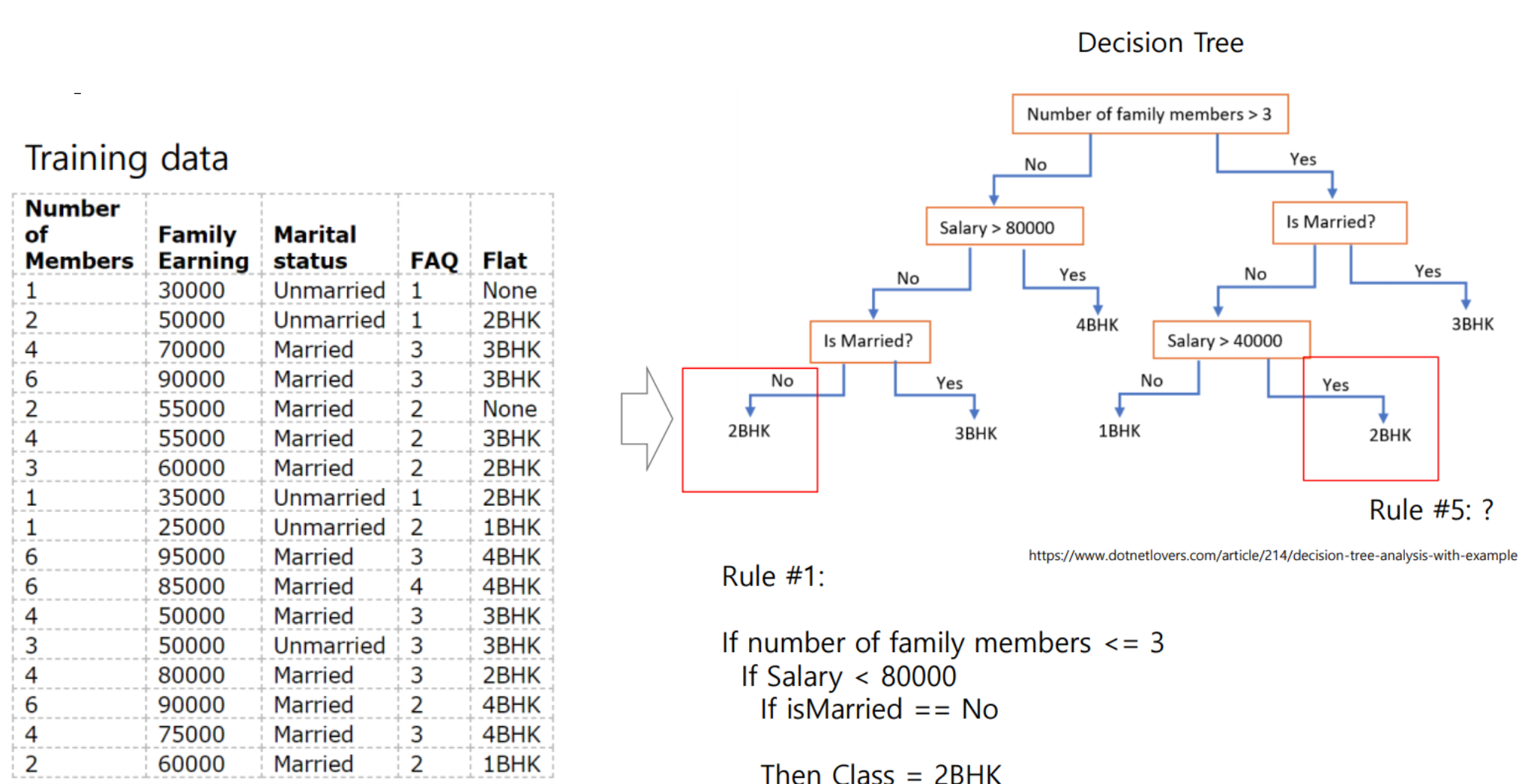
위 사진은 가족의 구성원이나 구입에 따른 집의 형태를 분리한 예제이다.
표에서 Number of Members, Family Earning가 input이 되고 Flat가 output, 즉 우리의 타겟 값이 된다.
오른쪽의 DT에서 가장 위인 루트 트리에서 구성원의 수로 분기하고, 이후 급여나 결혼 유무 등에 따라 분기하고 있는 모습을 확인할 수 있다.
이러한 트리는 트레이닝 데이터를 통해 잘 분류할 수 있게 만드는데,
새로운 테스트 데이터는 이미 트레이닝 데이터를 통해 생성한 DT로 예측이 가능하다.

또 다른 예로 자동차의 구매 목적에 대한 분류가 존재한다.
자동차는 마력과 토크의 값에 따라 Exotic, Fun driving, High Speed, Family, Economy 등으로 분류가 가능하다.
HP, 즉 마력을 200을 기준으로 분기한 후 토크의 값을 통해 분기를 진행할 수 있다.
우측의 그래프를 통해서 분류 결과를 확인할 수 있는데, 분류 결과에 어떠한 클래스도 섞여있지 않다. 즉, 분류 정확도가 100%이다. 따라서 위 모델을 통해 새로운 테스트 데이터(자동차 값)에 대해서 DT를 통과시킴으로써 원하는 결과를 얻을 수 있다.
앞의 예시를 통해 우리는 DT의 특징을 확인할 수 있다.
1. 해석이 용이하다.
어떤 값을 가지면 어떤 분류에 속하는 것이 명시적으로 드러난다.
2. 연산량이 적다.
DT를 미리 생성해두면, 테스트 데이터에 대한 연산량이 적다. 생성해 둔 DT에 대해 IF-THEN 룰만 따라가면 되는데, 이러한 연산은 어렵지 않기 때문이다.
또한 학습에서도 많은 연산량을 사용하지 않는다. 그리디 알고리즘을 사용하기 때문에 데이터를 한 번만 분류 했을 때의 분류 성능이 가장 높은 경우를 채택하기 위한 계산만 진행되기 때문이다.
따라서 연산량이 적고 해석이 간단하다.
3. 성능이 뛰어나진 않다.
축에 따라 feature를 나누는 방법의 한계일 수도 있는데, 이러한 DT의 성능은 크게 뛰어나지 않다.
Decision rule
DT 생성 시 규칙을 살펴보자.
- Axis-orthogonal
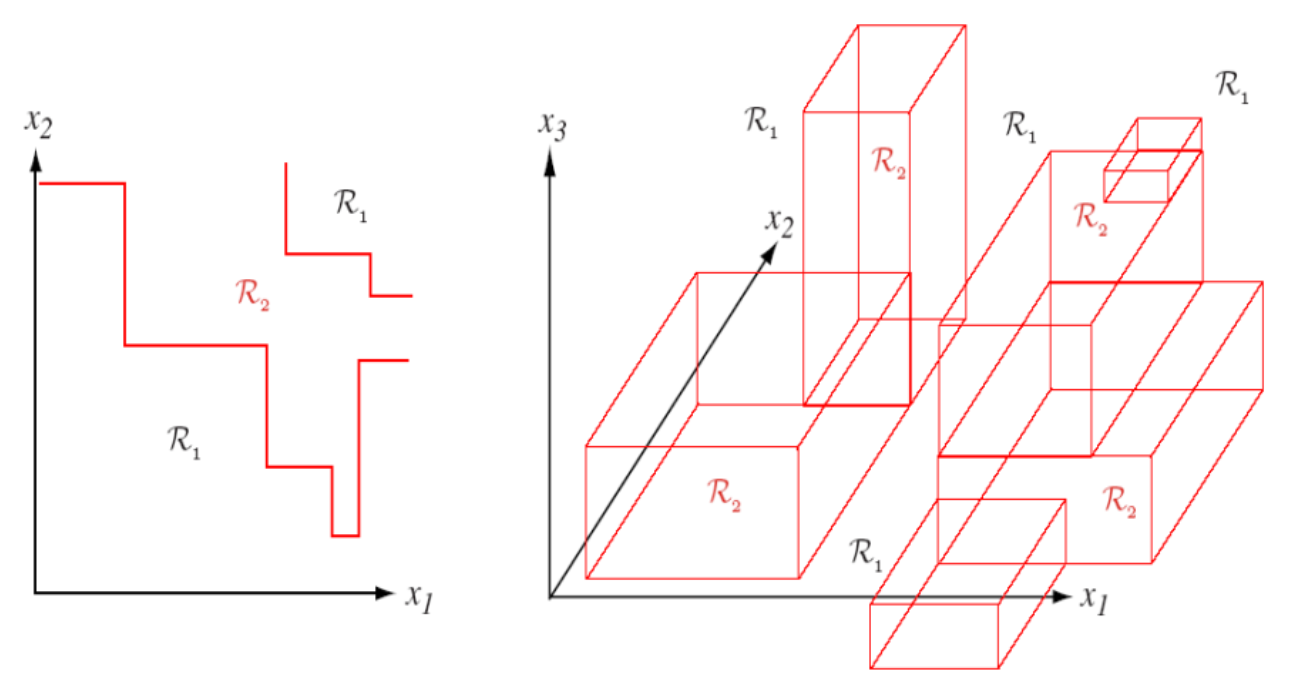
모두 feature를 기준으로 나눈다. feature를 기준으로 큰지, 작은지,
혹은 nominal value인 경우 어떤 값을 가지냐, 안 가지냐로 구분할 수 있다.
우리가 DT를 생성할 때 어떤 변수로 구성할 것인지, 해당 변수들은 어떤 값을 기준으로 파티셔닝 할 것인지 등을 결정해야 한다. 이러한 것을 결정하는 기준을 impurity라고 한다.
우리는 리프 노드에서 얼마나 잘 분류 되었는지를 확인할 수 있다. 이때, 리프 노드, 즉 분류된 결과에 다른 클래스 값이 얼마나 섞여있는지를 impurity라고 하며 한국어로는 불순도라고 할 수 있갰다.
따라서 우리는 impurity drop를 기준으로 불순도를 얼마나 낮출 수 있는지를 확인할 수 있다.
Impurity measurements
불순도를 측정하는 방법은 아래와 같다.
Entropy

Entropy는 불확실성에 대한 지표를 구할 수 있다.
Variance
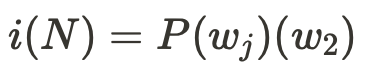
분산값으로, 분포가 얼마나 흩어져 있는가에 대해서도 측정할 수 있다.
Gini index
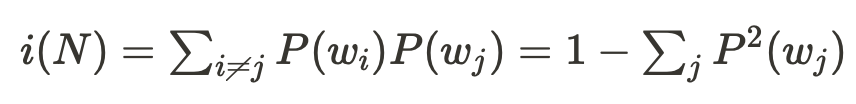
두 개의 서로 다른 클래스에 대해 분산보다 지니 인덱스 방법을 더 많이 사용한다.
Misclassification
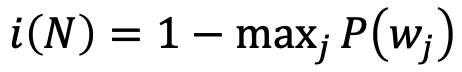
가장 높은 비중을 차지하는 클래스의 확률을 빼주는 방법이다.
따라서 가장 많은 쪽으로 분류했을 때에 잘못 분류할 확률이다.
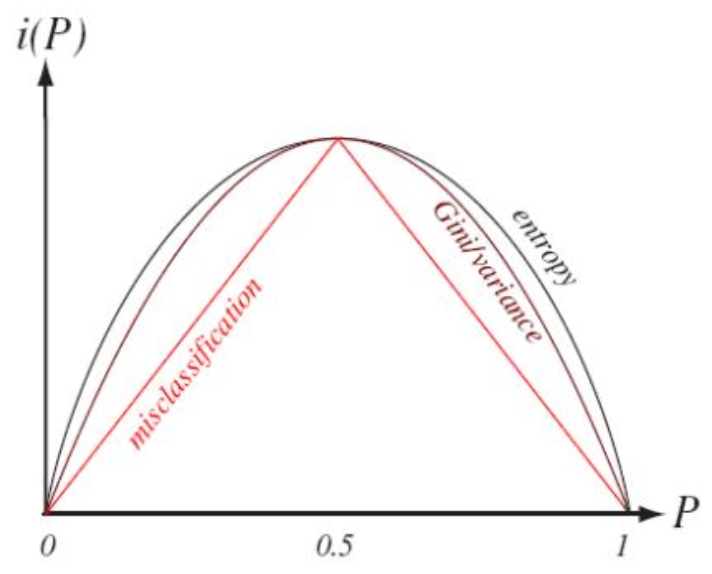
우리는 주로 Entropy, Giniindex, Misclassification 방법을 주로 사용한다.
사실 어떤 방법을 써도 상관이 없는데, 위 세 가지 값들이 거의 비슷한 분포를 가지므로 수치 상의 차이는 존재하지만 경향이 비슷하다.
따라서 각자, 더 큰 값을 가질 수록 더 많은 클래스가 섞여있다. 즉, 불순도가 높다고 이야기 할 수 있다.
Gini index vs. Entropy

위 사진은 Gini index와 Entropy의 값을 비교한 결과이다. 어떤 Impurity measure를 사용하느냐에 따라 경향은 비슷하지만 값이 달라 결과가 바뀔 수 있다.
위 사진에서 Entropy의 값은 A에서 더 높지만, Gini index의 값은 B에서 더 높다.
Split criteria
우리는 이제 변수를 split 해야 한다. 이 split을 통해 불순도가 얼마나 떨어지는지를 관찰한다. 즉, 어떤 기준으로 변수를 나눴을 때의 불순도 평균값이 현재의 불순도값과 비교 했을 때 더 작아야 한다.
따라서 우리는 불순도를 얼마나 떨어트릴 수 있는지를 기준으로 split의 기준을 정해준다.
- Information gain

이떄 불순도를 떨어트리는 것은 Information gain이 있다고 이야기하는데,
정보 이론에서 불순도가 떨어지는 것은 어떠한 정보가 많아진다고 한다.
즉, 리프 노드에 대한 정보가 높아진다.
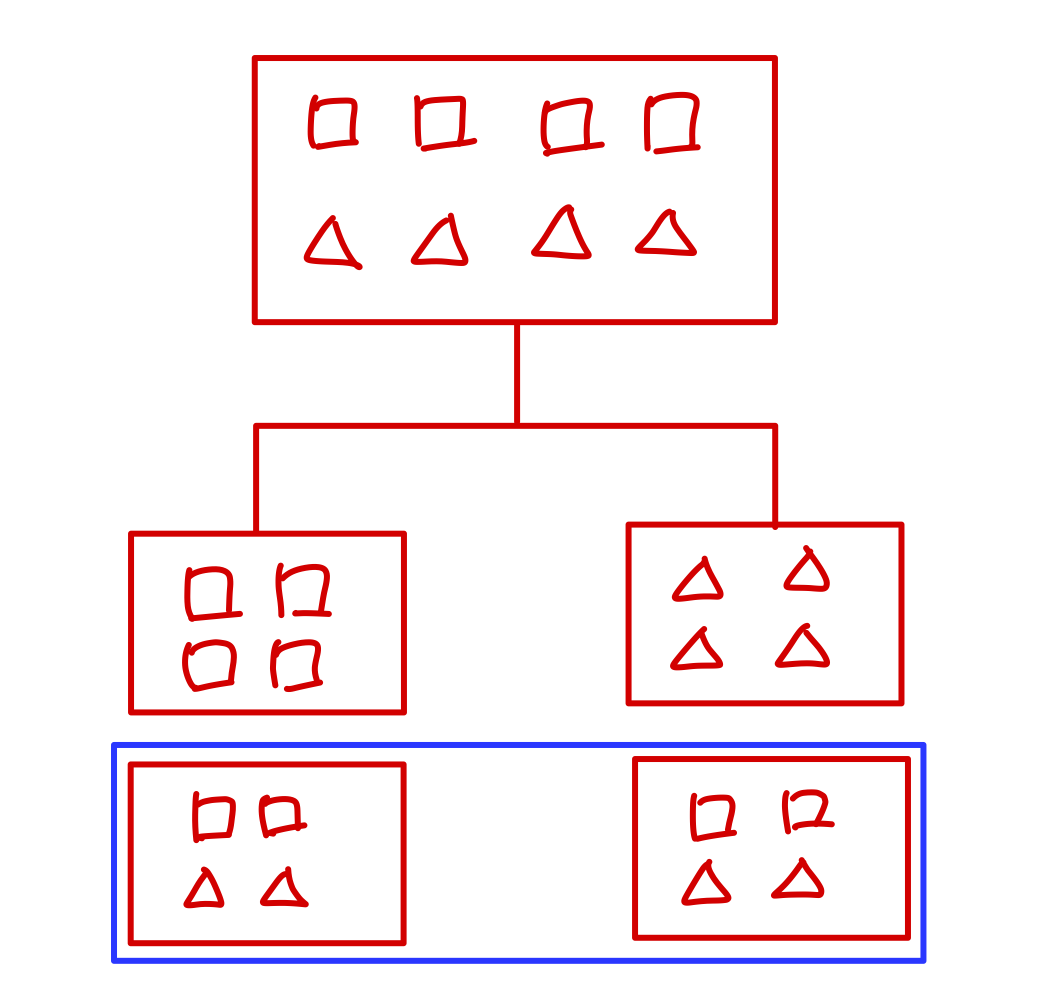
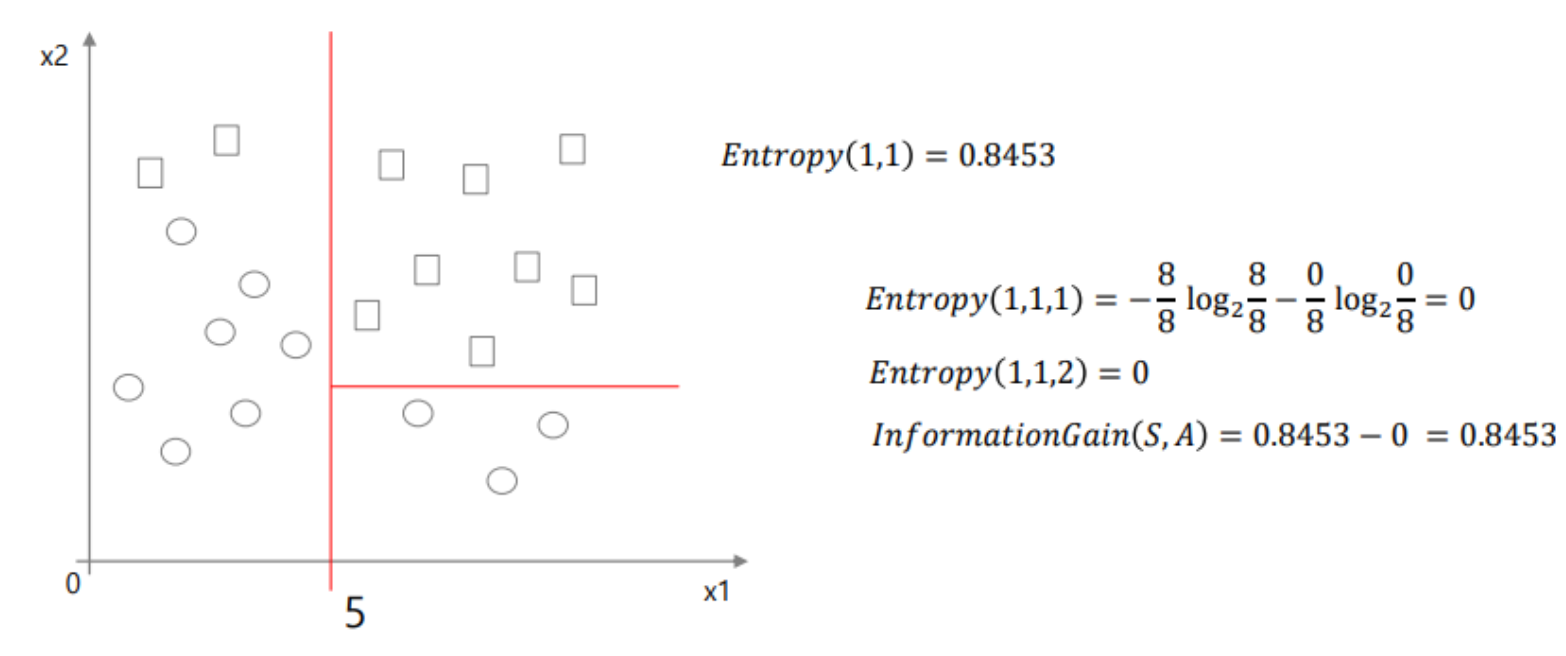
예를 들어보자.
위 사진과 같이 사각형이 4개, 삼각형이 4개일 때, 두 가지의 방법으로 파티셔닝을 진행할 수 있다. 그런데 파란색 박스 안의 경우 분류를 통해 얻을 수 있는 정보가 0에 가깝다. 반면 파란색 박스 위의 경우 각 리프 노드가 해당 데이터에 대한 정보를 얻을 수 있다.
따라서 불순도를 떨어트리는 것은 Information gain이 가능하기 때문에 해당 값을 구해줄 수 있다.
- Impurity drop
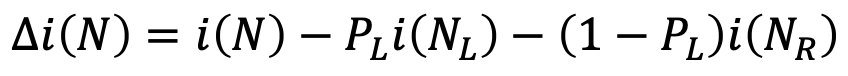
Impurity drop이란 불순도가 얼마나 떨어졌는지 확인할 수 있는 방법이다.
현재의 불순도 i(N)에서 split 이후 왼쪽 노드의 불순도 i(NL)과 오른쪽 노드의 불순도 i(NR)에 각 왼쪽으로 분류될 확률, 오른쪽으로 분류될 확률을 곱하여 뺄셈함으로 구할 수 있다.
아래 예시를 통해 인퓨리티를 구해보자.
예시1)
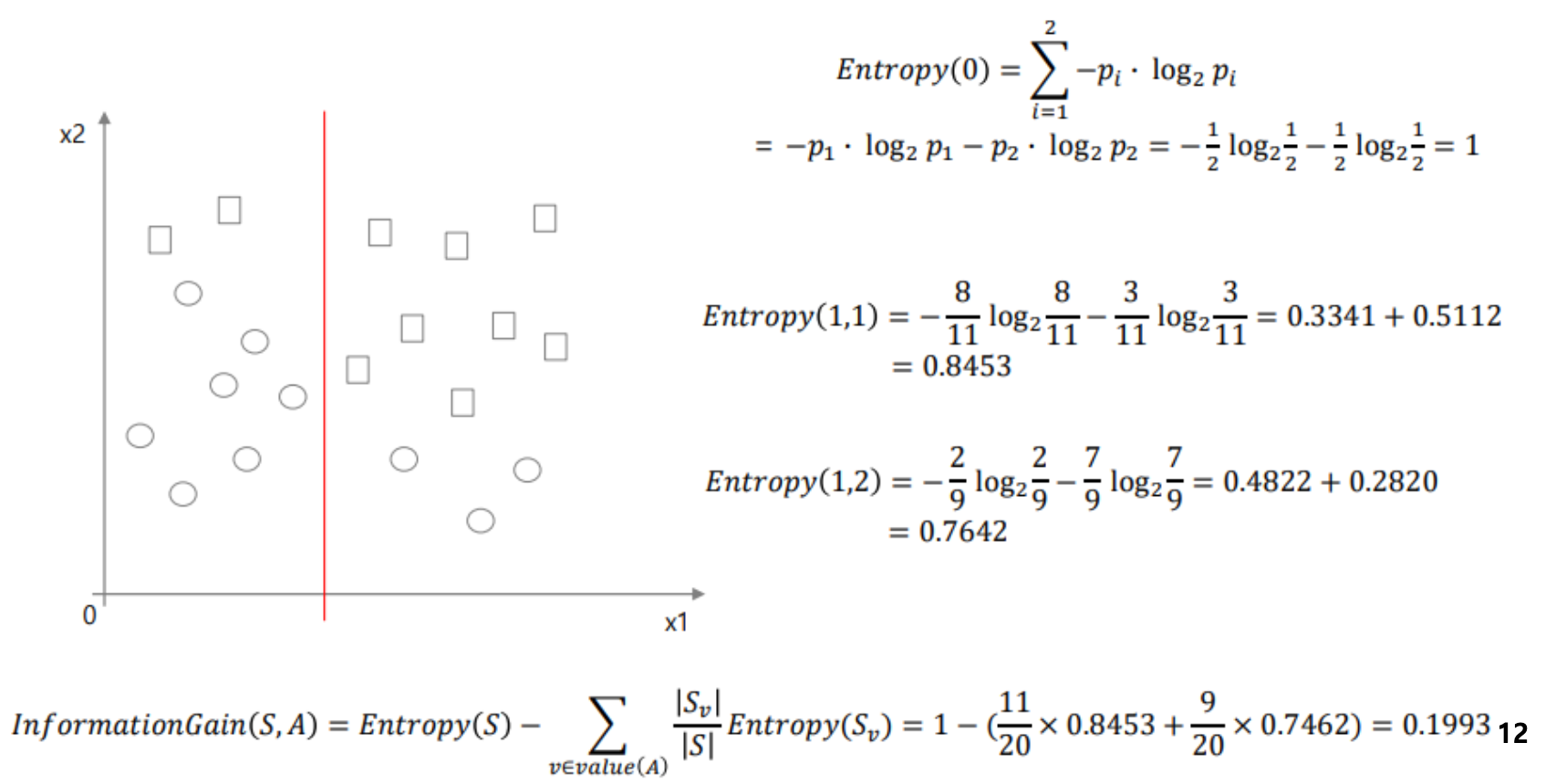
예시2)

예시 3)
recursive한 partining를 수행한다.

따라서 위의 DT가 생성된다.
Full Tree(full grown tree)

recursive한 파티셔닝을 계속 수행하다 보면 위와 같이 모든 클래스에 대해 완벽히 분류할 수 있는 full tree를 만들 수 있다. 그러나 위와 같이 분류하는 것은 모델 성능에 썩 좋지 않다.
위 사진은 oerfitting의 형태로 트리가 복잡하고 여러 분기를 만들수록 불순도는 적어지지만 일반화된 성능을 얻지 못한다. 따라서 우리는 분기를 어디까지 해야하는지에 대한 고민을 해야 한다.
Greedy method
DT를 생성할 때에는 그리디 알고리즘을 사용한다고 하였다.
그리디 알고리즘은 현재에 대해서 가장 잘 나누고, 성능이 떨어질 것 같아도 다시 되돌아가지 않는 특성이 있다. 따라서 지금 당장의 모습만 보고 데이터를 나누기 때문에 연산략이 상대적으로 적다.
하지만 DT는 성능이 떨어지는데, 그 이유는 모든 것을 고려하여 분류 기준을 만드는 것이 아니기 때문에 local optimum에 빠지기 때문이다.
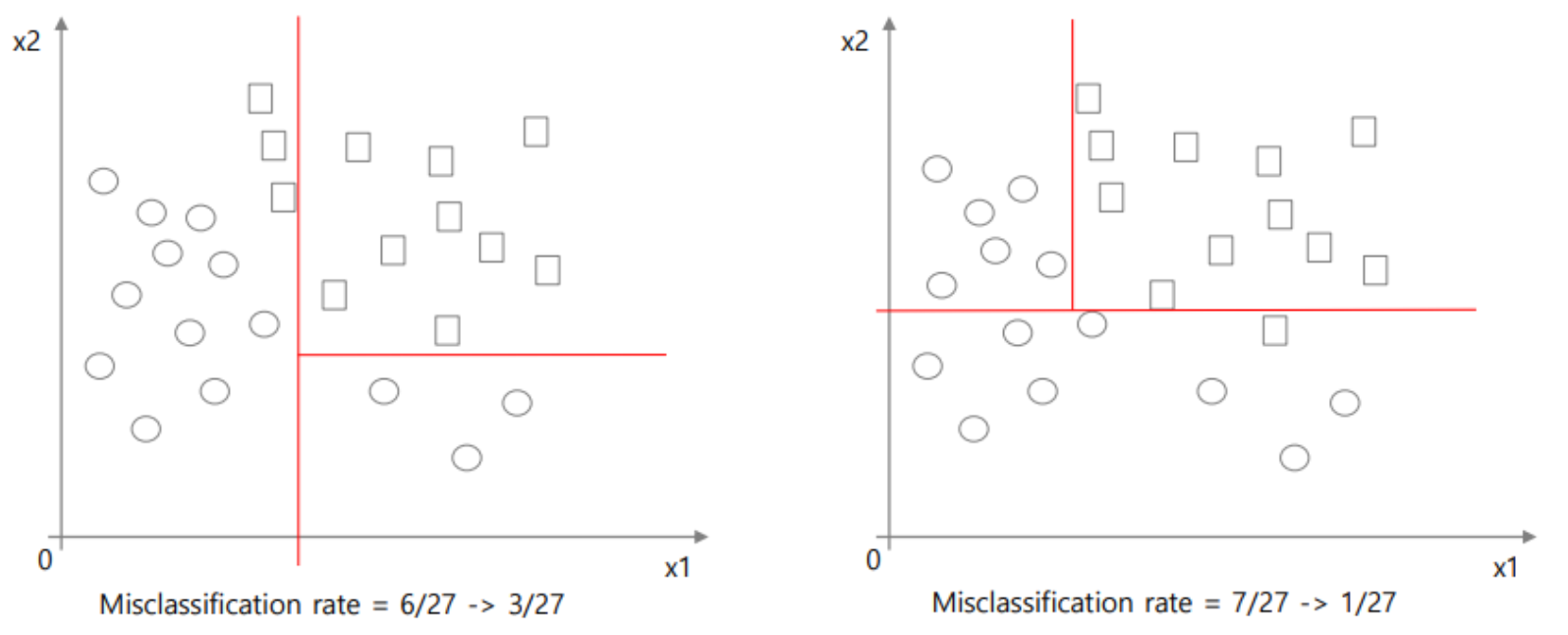
When to stop?
DT를 생성할 때에 분기는 끝도 없이 만들 수 있다.
그러나 분기를 너무 많이 생성하는 경우 overfitting이 될 수도 있고,
분기를 적게 생성하여 트리의 크기가 작은 경우 underfitting이 될 수 있다.
즉, 앞서 배운 오버피팅과 같이 학습 데이터에 대한 성능이 뛰어날 수록 overfitting 문제가 발생한다.
이러한 문제를 해결하기 위해서는 일반적으로 ML에서 사용하는 방법인
70%의 데이터로 학습시키고, 30%의 데이터로 validation을 진행하여 학습되지 않은 데이터에 대해 얼마의 성능을 보이는지 확인해준다.

벨리데이션 방법 외에도 overfitting을 제한하는 방법이 존재한다.
- Max depth
트리의 깊이를 제한하는 방법
- Max leaf nodes
리프 노드의 최대 수를 제한하는 방법
- Min data for split
split된 리프 노드에 대하여 해당 노드가 가질 수 있는 데이터의 최소량을 제한하는 방법
- Regularization
정규화를 통해서도 트리의 크기를 제한할 수 있다.
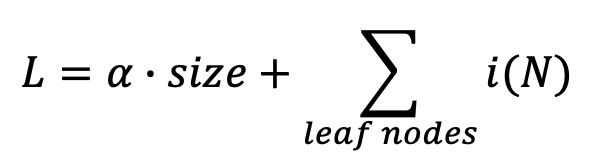
DT는 불순도(inpurity)를 낮추는 것이 목적이다.
일반적으로 다른 모델에 대해 정규화를 진행할 때 loss와 weight 크기 등을 고려하여 정규화를 진행하였다. 이러한 점을 DT에 대입하여 트리의 크기를 loss에 추가해줄 수 있다. 따라서 inpurity만을 낮추는 것이 아니라 트리의 크기를 줄이는 쪽으로 학습할 수 있다.
Pruning
프루닝은 오버피팅을 낮추는 가장 일반적인 방법이 된다.
프루닝은 가지치기라는 뜻으로 DT가 너무 커지지 않도록 가지를 쳐준다.
가지를 치는 기준은 풀 트리를 생성한 후 분기했을 때의 장점인 불순도를 낮추는 정도와 단점인 트리의 크기가 커지는 점을 비교하여 장점이 더 크면 유지하고, 단점이 더 크면 해당 가지를 잘라냄으로써 정규화를 진행할 수 있다.
가지를 칠 때에는 siblings, 즉 같이 태어난 노드들은 한 번에 쳐준다.
이 과정에서 validation 데이터를 사용하지는 않지만, full 트리를 생성한 이후 각 가지에 대해 평가를 하기 때문에 연산량이 증가한다.
이때 비용을 계산하는 방법은 아래와 같다.
Cost = training error + tree size (cost-complexity pruning)
프루닝을 진행한 후에도 비용이 증가하지 않으면 해당 노드는 의미가 없다.

이때 α값을 통해 트레이닝 에러와 트리 사이즈의 가중치를 둘 수 있다.
프루닝의 알고리즘을 보자.
1. full tree를 생성한다.
2. Pruning를 진행한다.
프루닝 시 sub-tree를 찾아야 하는데, sub-tree는 풀트리에서 어떤 리프 노드에 대해 해당 노드를 제외한 트리를 sub-tree라고 한다. 이후 풀트리에 대한 코스트가 서브트리의 코스트보다 높으면 서브트리를 선택한다.
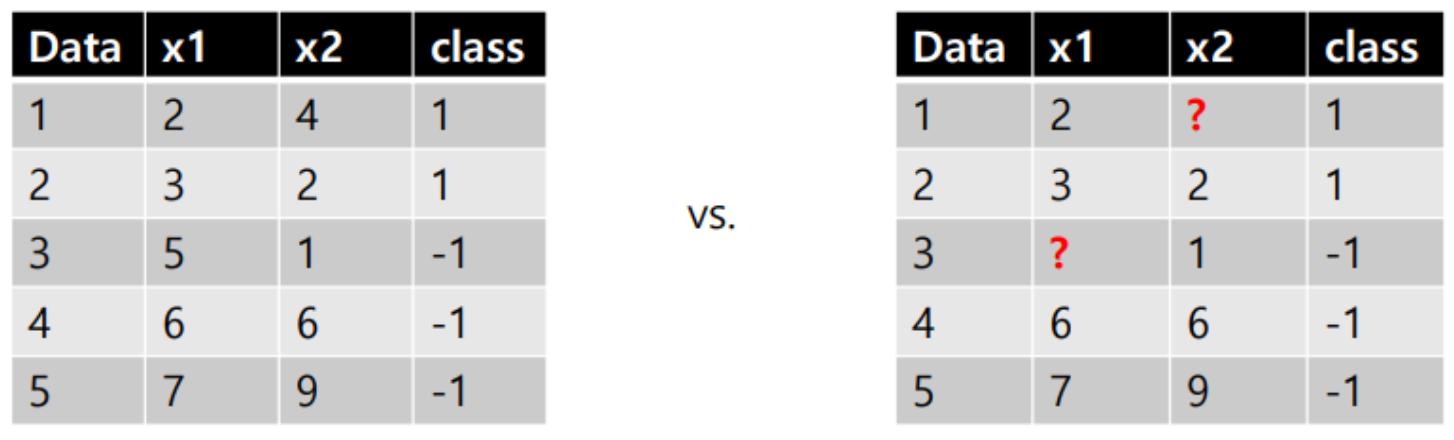
Robustness to nominal variables, outliers, missing values
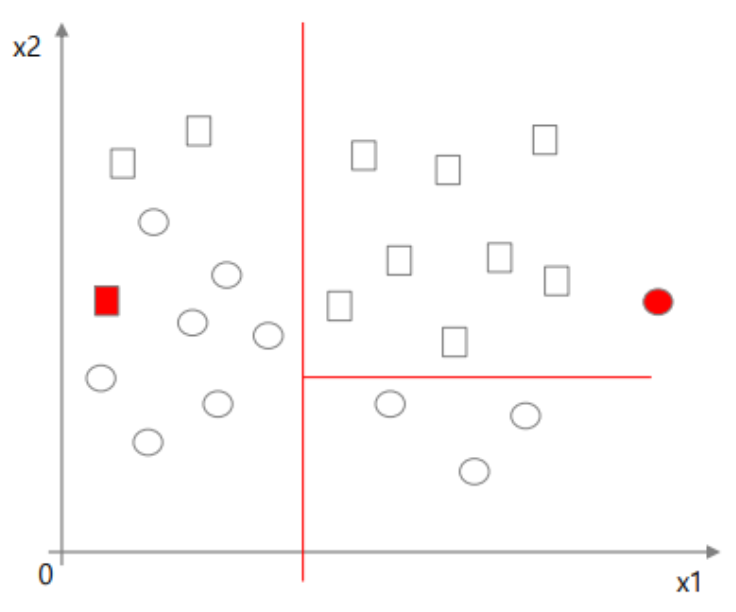
- nominal variables
수치가 아닌 값에 대해서도 분기를 잘 진행할 수 있다.
- Outliers(튀는 값)
DT는 Outliers에 대해 굉장히 둔감하게 반응하기 때문에 튀는 값이 존재해도 모델의 성질이 변하지 않는다.
- missing values(결측치)
사라지거나 손상된 값으로 DT 구성 시에 크게 문제가 되지 않으며 missing values에 대한 분기를 따로 만들어줄 수도 있다. 또한 랜덤으로 어떤 클래스에 넣을 수도 있다.
Variable selection
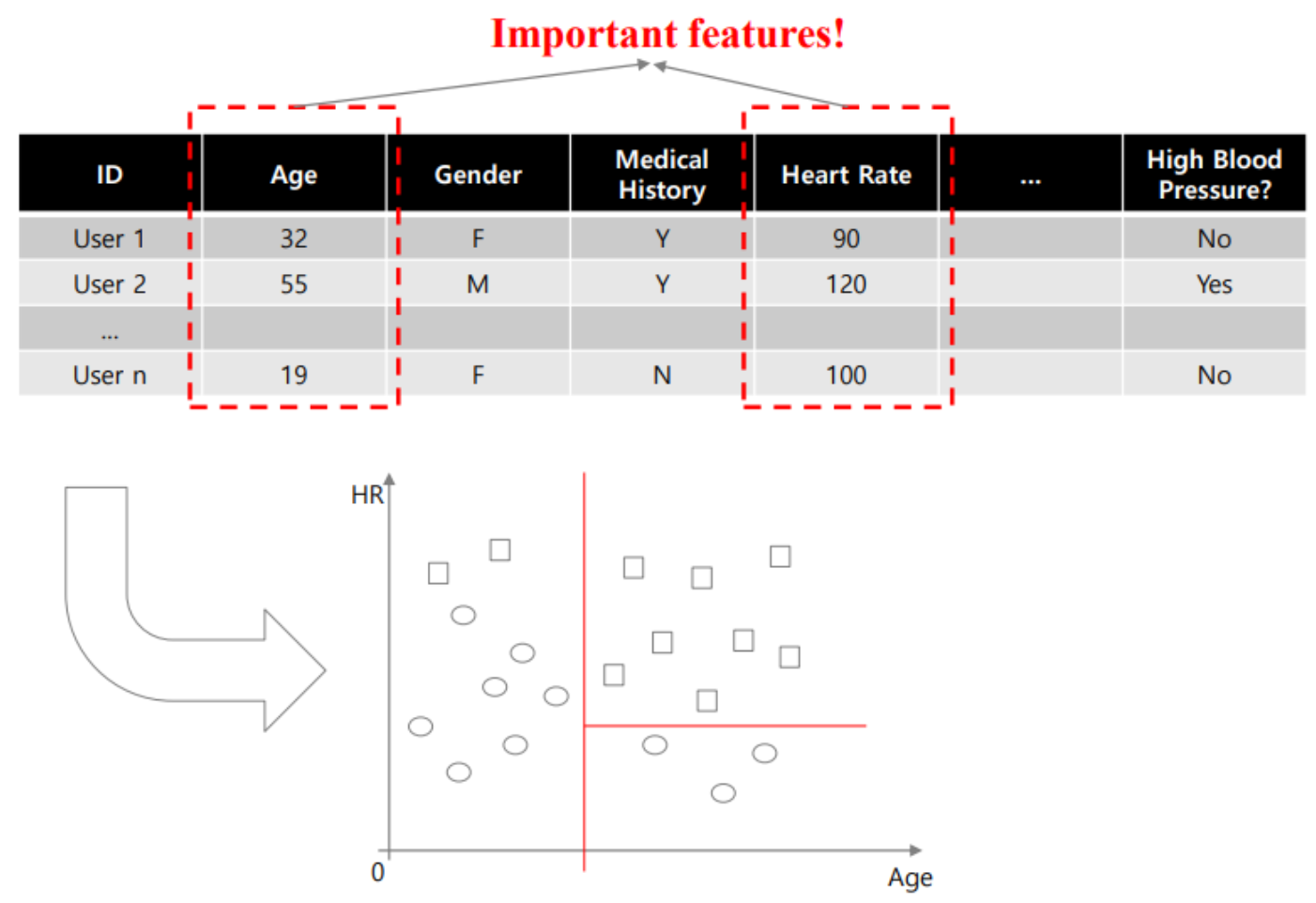
사진과 같이 분류할 때 특정한 피처가 중요한 피처인 경우 초반 분기로 나눠줄 수 있다.
반대로, 어떤 DT를 구성하는 알고리즘을 사용했을 때 초반에 나눠지는 분기가 중요한, 또는 크게 나눠주는 분기라고 해석할 수 있다.
따라서 이렇게 중요한 피처를 찾을 수도 있고, 특정 피처에 대해 선택도 가능하다.
Nonlinear splits
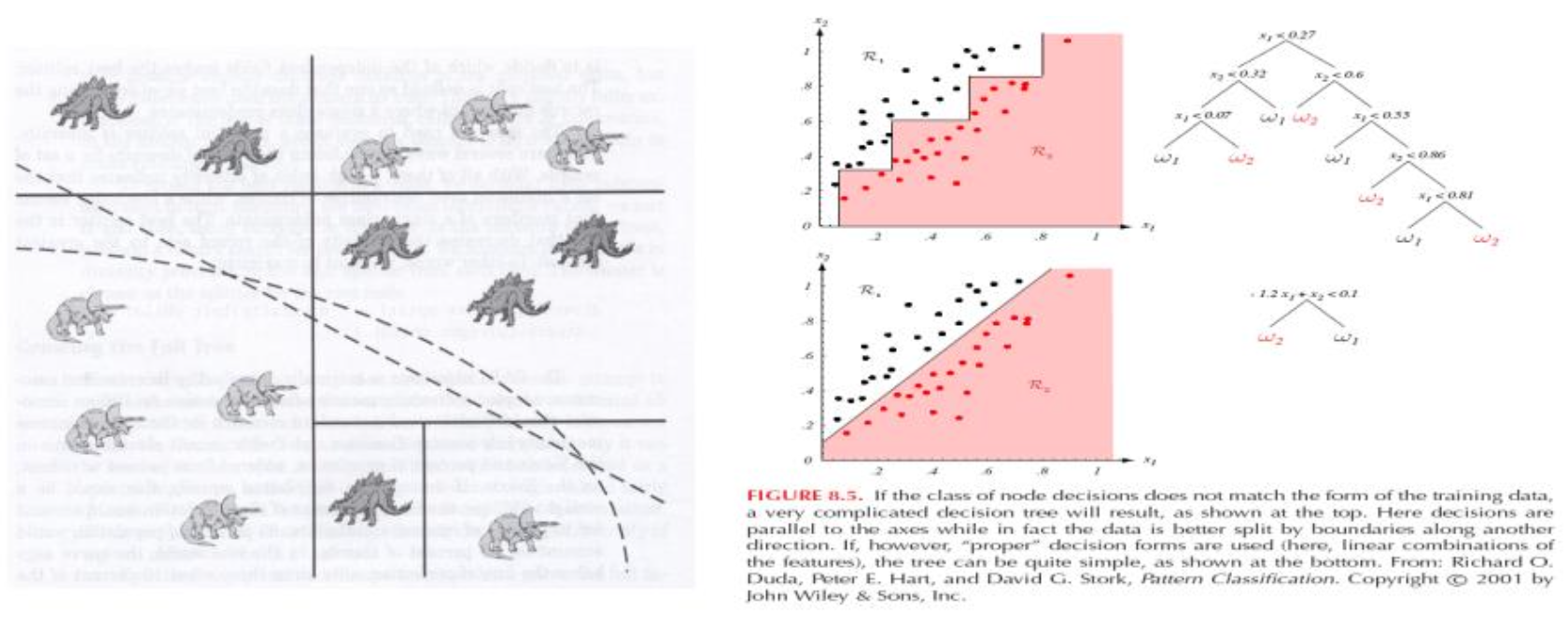
DT는 위 사진과 같이 nonlinear하게 스플릿할 수 있다.
즉 Axis-orthogonal partitioning 방법이 아닌 여러 가지 논리 기준으로 분기가 가능하다.
이렇게 분기를 진행하는 경우 DT의 성능을 높여줄 수 있다.
하지만 DT의 장점 중 하나인 해석력을 떨어트린다는 문제가 존재하기 때문에 성능과 해석력이 trade-off관계를 가진다.
orthogonal한 파티션을 여러 개 두면 트리가 커지는 단점을
non-linear를 이용한 분기를 통해 리니어로 근사해줄 수 있다.
꼭 non-linear 분기를 이용해야 하는 것은 아니지만, linear를 통해 분류 성능을 높이는 것은 트리가 복잡해지는 단점이 존재하기 때문에 non-linear를 이용한다.
Decision tree regression
DT는 분류 뿐만 아니라 regression에서도 사용할 수 있다.
따라서 입력에 대해 결과를 예측해줄 수 있는데, regression에서는 불순도를 측정하는 것이 아니라 에러를 통해 실제 값과의 차이로 분기를 더 할지 말지를 결정한다.
따라서 에러가 너무 크다거나 리프노드의 값이 실제 값의 베리언스가 큰 경우 분기를 더 진행한다. 따라서 더 같은, 비슷한 값을 갖는 타겟끼리 묶일 수 있도록 분기를 진행한다.
Decision tree algorithms

DT를 생성할 때 분기를 해주는 기준은 구하는 여러 알고리즘이 존재한다.
일반적으로 많이 사용하는 알고리즘은 CART이다.
위 사진과 같이 DT를 생성하는 알고리즘은 split criteria, pruning, attributes 등 성질에 따라 여러 종류가 존재한다.
⭐️ 정리
DT는 if-then rule을 사용하여 이해가 쉽고 해석이 가능한 규칙이 형성된다.
또한 Variable selection & reduction이 자동으로 수행되고
어떤 데이터의 분포에 대해 가정이 필요하지 않다.
또, missing data를 버리거나 특별한 보간법(Interpolation)없이 활용이 가능하고
Pruning를 통해 regularization이 가능하다.
'Computer Science > 기계학습 (Machine Learning)' 카테고리의 다른 글
| [기계학습/ML] Neural Network (1) | 2023.12.18 |
|---|---|
| [기계학습/ML] Ensemble Method (1) | 2023.12.17 |
| [기계학습/ML] Bayesian Classifier (1) | 2023.10.23 |
| [기계학습/ML] Introduction to ML (2) | 2023.10.23 |
| [머신러닝/ML] ConvNet (0) | 2023.07.26 |