우리는 지금껏 많은 데이터들로 모델들을 학습시켰다.
해당 모델을 평가하려면 어떻게 해야 할까?
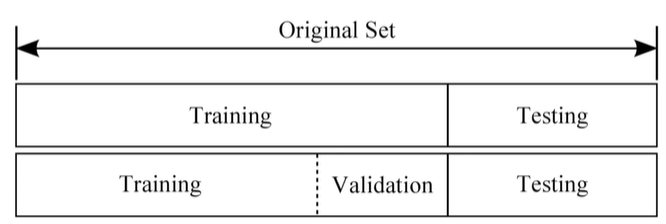
우리는 지금껏 모델을 학습시킬 때 사용한 데이터들을 training set이라고 불렀다.
평가를 할 때에 training set을 이용한다면 정확도에 100%에 달할 것이다.
따라서 우리가 보유하고 있는 데이터들을 잘라
일부분은 학습 용도, 일부분은 평가 용도로 사용한다.
보통 70%를 training set, 30%를 testing set으로 사용한다.
testing set을 모델에 넣은 후 기댓값과 결과값을 비교하여 모델을 평가한다.
우리는 앞서 학습률(learning rate)라고 불리는 α와
데이터의 regularization 시 정규화 강도를 표현하는 λ를 학습하였다.
training set을 일정 비율로 쪼개 일부는 모델을 학습시킬 때 사용하고,
일부는 위의 상수값들을 튜닝할 때 사용한다.
상수값을 튜닝할 때 사용되는 데이터 set은 validation set이라고 한다.
validation set은 고등학생들이 수능을 모의로 풀어보는 모의고사와 비슷하다.
Online Learning
우리가 가지고 있는 데이터의 양이 방대하면
그 데이터들을 모두 넣어 모델을 학습시키기 어렵다.
따라서 우리는 Online Learning 방법을 사용한다.
이는 수많은 데이터들을 쪼개어 각 조각별로 학습을 시키는 것이다.
이때, 새로운 조각을 넣어 학습을 시킬 때 이전의 조각으로 학습된 내용을
모두 가지고 있어야 한다.
이러한 Online learning의 장점은 이미 학습된 모델이 존재하고
traning set에 새로운 데이터가 추가되었을 때,
데이터 전체를 다시 넣어서 학습을 시키는 것이 아닌 추가된 데이터만으로
모델에게 학습을 시킬 수 있다는 점이다.
Minist Dataset

유명한 data set 중 하나로 사람들이 손으로 작성한 숫자를
컴퓨터가 인식할 수 있는 숫자로 바꿔주는 모델을 학습시킬 때 사용하는 data set이다.
이러한 모델은 우체국에서 우편번호를 인식해낼 때 사용한다.
Accuracy
모델의 정확도를 판단하는 방법은 간단하다.
모델에 testing set을 넣고 결과값을 기댓값과 비교한 후
전체 testing set에 대한 정답의 비율을 구하면 된다.
최근 개발되는 이미지 인식 모델들의 정확도 95% ~ 99%이다.
'Computer Science > 기계학습 (Machine Learning)' 카테고리의 다른 글
| [머신러닝/ML] XOR연산 딥러닝으로 풀기 (0) | 2023.07.21 |
|---|---|
| [머신러닝/ML] 딥러닝의 기본 개념 (0) | 2023.07.20 |
| [머신러닝/ML] Learning Rate, Data Preprocessing, Overfiting (0) | 2023.05.20 |
| [머신러닝/ML] Softmax Classification / Multinomial Classification (0) | 2023.05.18 |
| [머신러닝/ML] Binary Classification / Logistic Regression (0) | 2023.05.18 |