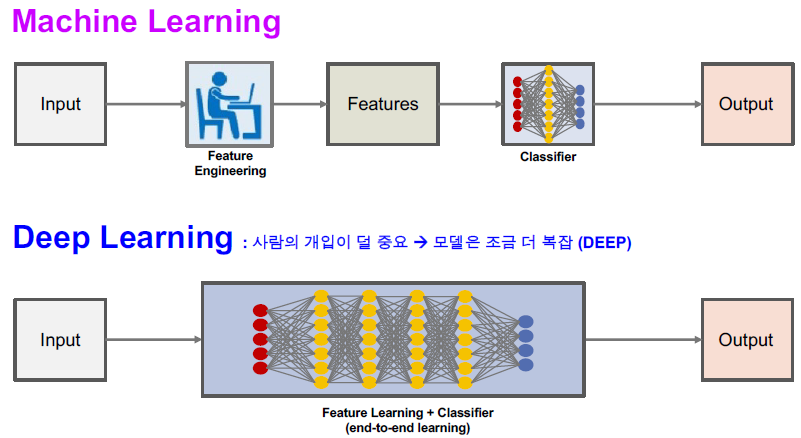
머신러닝에서 딥러닝으로 발전한 까닭이 존재한다.
머신러닝은 training set에 대해 사람이 feature를 추출하여
추출된 feature를 바탕으로 각 모델들이 학습하였다.
하지만, 데이터에는 사람이 발견할 수 없는 많은 요소들이 존재한다.
사람이 feature를 추출하고 학습시킨 모델은
일정 양 이상의 training set이 들어오면 정확도가 더 이상 높아지지 않는
문제점이 발생하는 것이다.
따라서 사람이 feature를 추출하는 것이 아닌,
feature를 추출하는 일련의 과정마저 모델에게 맡기는 것이다.
새의 사진을 넣고 이러한 생김새를 가진 모든 사진을 새라고 명명하도록
각각의 데이터에 label만 붙여주는 것이다.
이러한 방식을 사용하면 정확도가 더욱 높아질 수 있다는 장점이 있으며
이와 같은 방식을 Deep Learning라고 한다.
하지만, 머신러닝에 비해 더욱 많은 학습 데이터가 필요하고
모델이 더욱 복잡해진다는 단점이 존재한다.
XOR 문제
우리는 컴퓨터로 인간의 뇌를 구현하는 것을 꿈꿔왔다.
하지만, 인간의 뇌는 복잡하게 구성되어 있다.
따라서 입력에 대해 일정 weight를 곱하고, bias를 더하여
인간의 뇌에 존재하는 뉴런을 모방하고자 하였다.
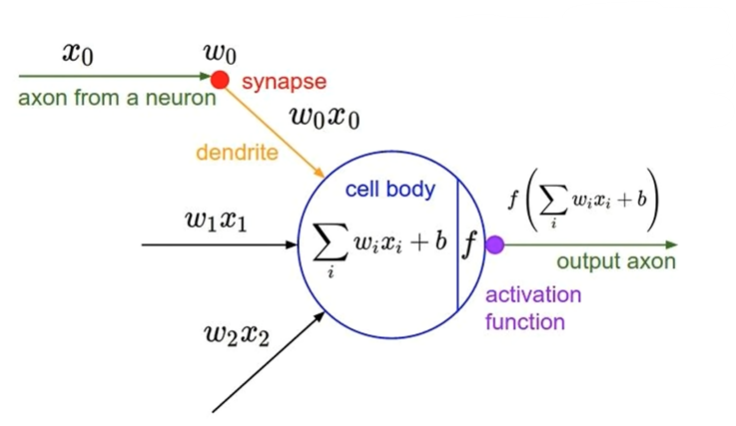
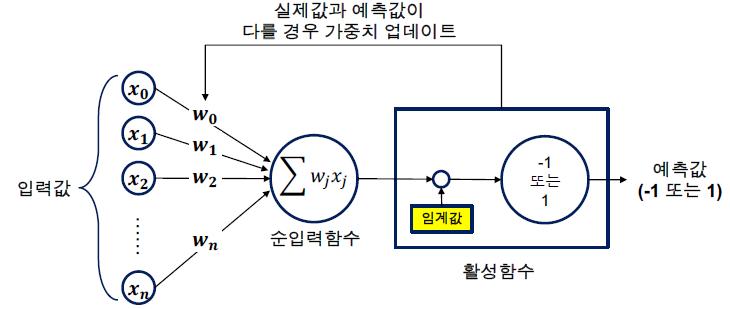
위의 식을 아래의 그림과 같이 나타낼 수 있다.
input layer에서 output layer로 가는 일련의 과정에서
w를 곱하고, b를 더해주는 것이다.
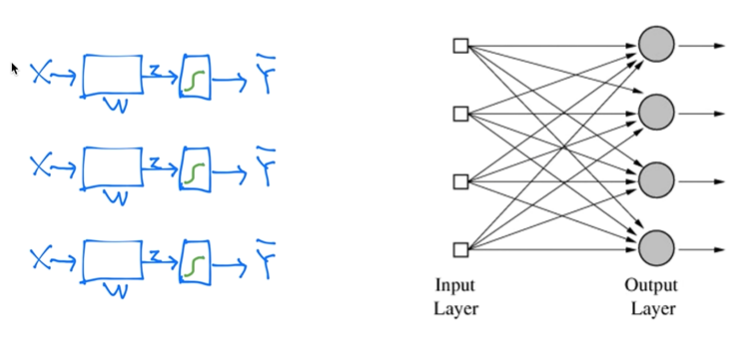
이러한 시도는 과거에서부터 꾸준히 이어져 왔다.
사람들은 OR/AND logic operation을 기계가 예측하도록 하였다.
컴퓨터는 2진법을 이용하여 0과 1로 표현하기 때문에
logic operation 중 가장 기본적인 AND와 OR 연산이 실행하는 것을 목표로 둔 것이다.
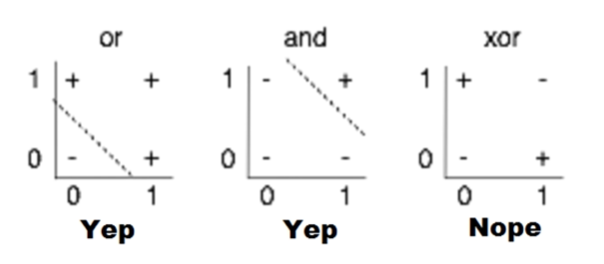
OR과 AND의 연산 방법 및 결과는 위의 사진과 같다.
두 개의 입력을 바탕으로 0 또는 1의 결과값을 출력하면 된다.
하지만, XOR의 연산은 어떠한 linear한 선을 그었을 때
연산의 결과값을 정확하게 예측할 수가 없다.
따라서 1969년 MIT의 인공지능 연구실에서는 현재의 단일 레이어로
XOR 연산을 구현해낼 수 없다는 결론을 내었다.
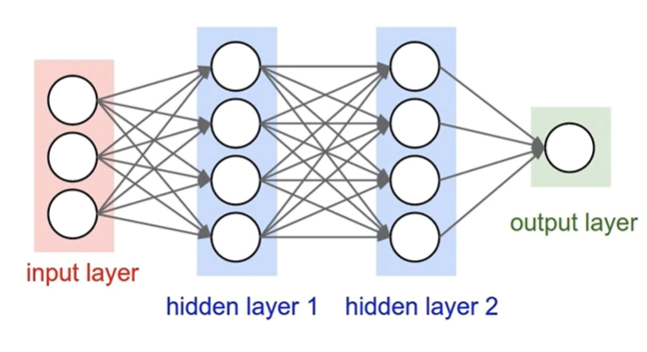
여러 개의 레이어를 사용해야 XOR의 연산이 가능하다는 연구 결과를 발표한 것이다.
이를 multilayer라고 하며 이러한 연구 결과는 많은 사람에게 실망을 준다.
multilayer를 구현하기 위해서는 새로운 weight값을 생성해야 하기 때문이다.
Backpropagation
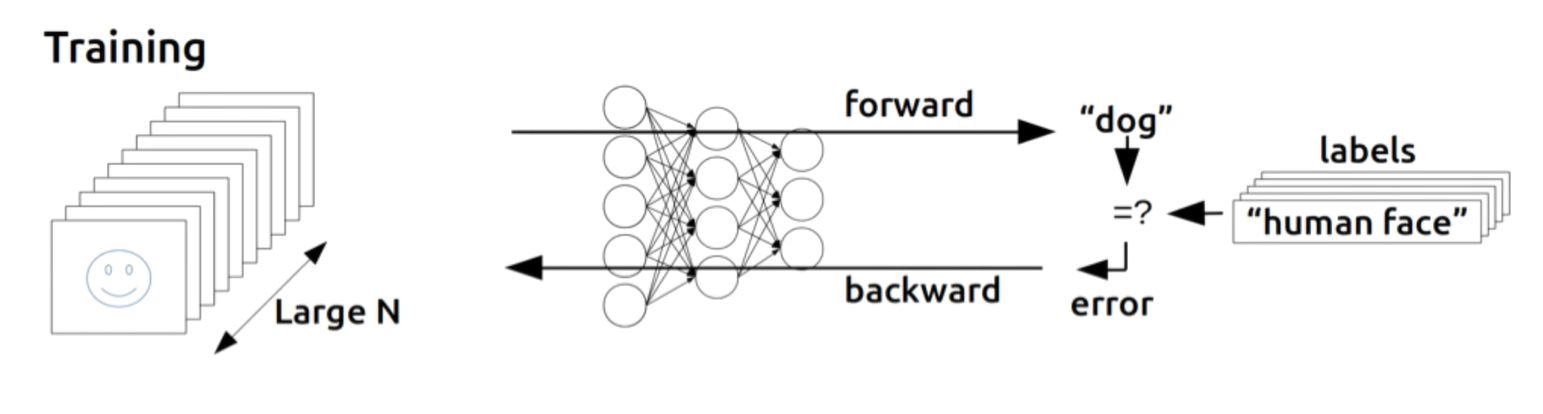
training set으로부터 w값과 b값을 획득하고 이를 조정해야 하는데,
이 과정은 사람이 하기에는 무리가 있다.
입력을 통해 출력을 만들어내고, 출력에 오류가 존재하는 경우
오류가 있는 w와 b를 알아내기 위해
일련의 과정을 거꾸로 복기하는 방법이 backpropagation이다.
하지만 layer의 개수가 엄청나게 많은 경우 backpropagation 방법을 사용하기에
유의미한 학습 결과를 도출하기가 어렵다.
'Computer Science > 기계학습 (Machine Learning)' 카테고리의 다른 글
| [머신러닝/ML] ReLU와 Weight 초기화 (0) | 2023.07.26 |
|---|---|
| [머신러닝/ML] XOR연산 딥러닝으로 풀기 (0) | 2023.07.21 |
| [머신러닝/ML] Training Set, Testing Set (0) | 2023.05.22 |
| [머신러닝/ML] Learning Rate, Data Preprocessing, Overfiting (0) | 2023.05.20 |
| [머신러닝/ML] Softmax Classification / Multinomial Classification (0) | 2023.05.18 |