ReLU
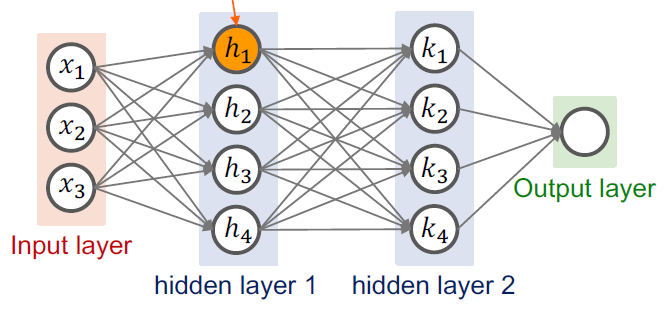
딥러닝은 여러 개의 레이어를 통해 학습이 진행된다.
이때 입력을 받는 레이어는 input layer,
출력을 만들어내는 레이어는 output layer라고 한다.
그렇다면 레이어의 개수가 많을 때,
input layer와 output layer를 연결해 주는 중간 레이어가 존재할 것이다.
우리는 이러한 중간 레이어를 hidden layer라고 한다.

하지만 레이어의 개수가 늘어나도 cost나 accuracy는 거의 그대로이다.
이는 backpropagation을 통해 적은 개수의 레이어를 사용할 때에는
weight값이나 bias값을 잘 찾아냈다.
하지만 레이어의 개수가 많아진 경우(9개 이상)
적절한 weight, bias값을 찾지 못한다.
hidden layer의 노드를 거칠 때 우리는 weight값과 bias값을 통해
들어온 input의 값을 변경시킨다. (linear function)
이후 다음 layer로 넘어가기 전에 sigmoid function을 거치면서 값을 조정한다. (activation function)
따라서 다음 레이어는 항상 이전 레이어로부터 sigmoid를 거친 값만 받는다.
이때 sigmoid function의 결과값은 대부분 1보다 작은 값이거나
0에 아주 가까운 값이다. 즉 소수점으로 나타나지는 값이다.
소수점으로 표현된 값들이 연쇄적으로 많이 계산되면
컴퓨터가 계산할 수 없는 소수점이 등장할 수도 있다.

소수점이 길어지면 값은 점차 0에 가까워져
backpropagation을 통해 계산되던 값은 점차 소실된다.(Vanishing gradient)
따라서 sigmoid를 과감히 버리고 새로운 activation function을 도입하기로 했다.
그것이 ReLU(Rectified Linear Unit) 함수이다.

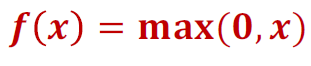
ReLU함수는 위와 같으며 양수일 때는 x,
음수일 때는 0의 값을 만드는 함수이다.
1. 함수가 매우 간단하고
2. 미분하기 편하며 (양수일 경우 1, 음수일 경우 0)
3. backpropagation에 유리하다.
위와 같은 장점을 통해
cost와 accuarcy의 값이 유의미하게 변화한다.
Weight의 초기화
만약 랜덤으로 설정한 weight가 0이 된다면
backpropagation으로 인한 미분을 통해
weight값이 0인 node의 모든 이번 노드에 대해
기울기 값이 0이 나오게 된다.
모든 기울기 값이 0이면 학습이 되지 않으므로
초기화를 잘 해주어야 한다.
이러한 문제를 해결하기 위해
Restricted Boatman Machine(RBM)을 제시하였다.
이 RBM을 사용하여 weight를 초기화한 것을 Deep Belief Nets라고 한다.
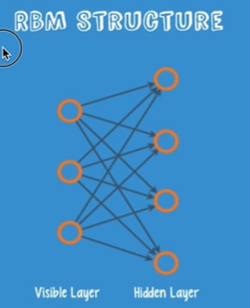
이를 restriction이라고 하는 이유는 node간의 connection이
앞뒤로만 연결되어 있기 때문이다.
작동 원리는 다음과 같다.
inpur값을 forward로 계산한 값을
다시 backward로 계산하였을 때 input값과 비교하였을 때
동일한 값이 나오도록 한다.
따라서 encoder, decoder라고도 한다.
RBM을 통해 weight를 어떻게 초기화할 수 있을까?
layer 중 앞뒤로 연결되어 있는 2개의 layer만 선택하여
앞뒤로 계산해가며 weight를 조정한다.
하지만 RBM을 직접 구현하는 것은 어렵다.
따라서 최근에는 간단한 초기값을 주어도 괜찮다는 연구결과가 발표되었다.
Xavier initialization의 방법은 2010년에 등장하였는데
각 노드에 입출력 개수에 비례하여 값을 초기화한다.
'Computer Science > 기계학습 (Machine Learning)' 카테고리의 다른 글
| [머신러닝/ML] ConvNet (0) | 2023.07.26 |
|---|---|
| [머신러닝/ML] Dropout과 Ensemble, 네트워크 쌓기 (0) | 2023.07.26 |
| [머신러닝/ML] XOR연산 딥러닝으로 풀기 (0) | 2023.07.21 |
| [머신러닝/ML] 딥러닝의 기본 개념 (0) | 2023.07.20 |
| [머신러닝/ML] Training Set, Testing Set (0) | 2023.05.22 |