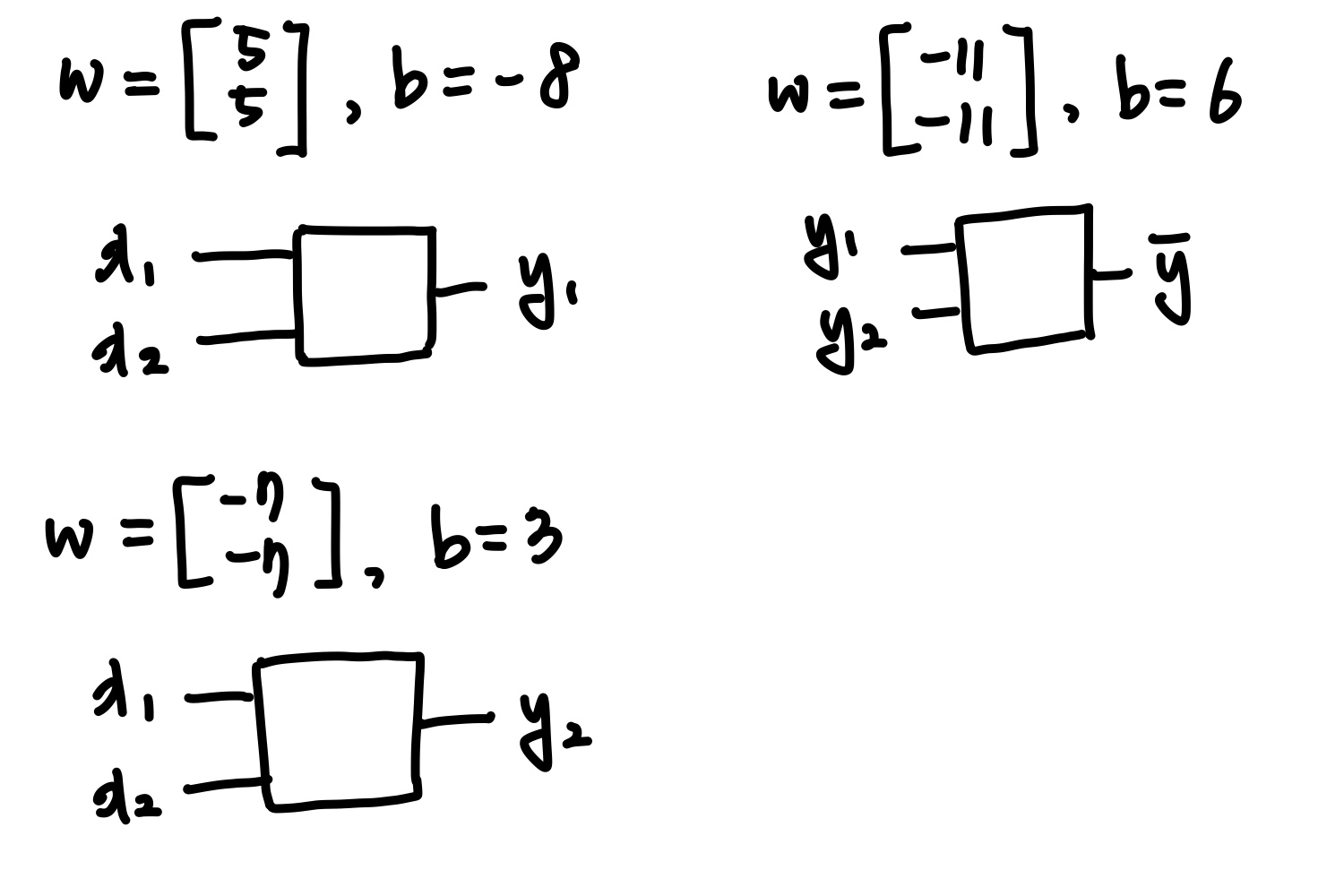[머신러닝/ML] XOR연산 딥러닝으로 풀기
앞서 XOR operation은 단일 레이어로 정답을 유추하기에 어려움이 있다고 언급하였다. 따라서 다중레이어 즉, multilayer를 사용해야 하는데 레이어가 증가할 수록 새롭게 정의해야 하는 weight값과 bias값이 증가한다는 문제점도 있다고 언급하였다. XOR 연산 풀어보기 3개의 unit의 weight와 bias를 임의로 설정하여 XOR연산을 풀이해보겠다. x1, x2의 입력을 넣어 각 y1, y2의 결과를 도출하고 y1, y2의 입력을 넣어 ȳ의 결과를 도출하게 한다. 이때, ȳ가 XOR연산의 결과가 되는 것이다. 각 레이어는 아래와 같이 계산한다. 이때 각 값을 구하는 S함수는 sigmoid함수로 앞서 언급하였다. 단순히 음수면 0의 값을, 양수면 1의 값을 도출한다고 생각해도 좋다. 첫..