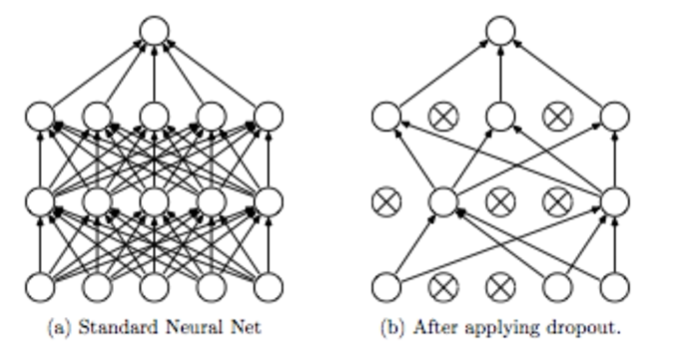
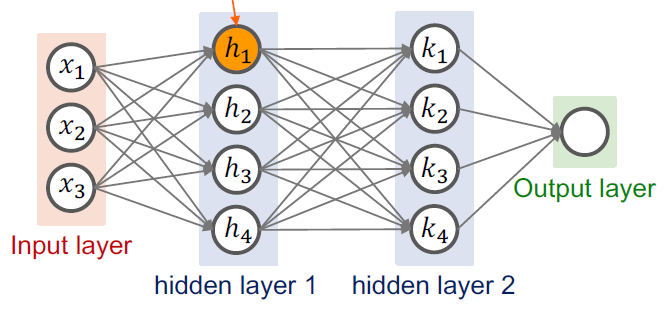
[머신러닝/ML] Dropout과 Ensemble, 네트워크 쌓기
Dropout과 Ensemble 이전에 우리는 Overfitting라는 것을 학습하였다. overfitting이란 학습 데이터에 대해 100%의 정확도를 내어 오히려 test data set에 대해 낮은 정확도를 보이는 경우를 말한다. 우리는 이러한 overfitting 문제를 해결하기 위해 regularization이라는 것을 학습하였다. 이해하기 쉽기 이야기 하자면, 꼬불꼬불하고 복잡하게 그어진 그래프를 일부 weight를 없앰으로써 평탄하게 만들어주는 것이다. 더 자세한 내용은 아래의 링크를 참고하기 바란다. https://coding-saving-012.tistory.com/90 [ML/머신러닝] Learning Rate, Data Preprocessing, Overfiting Learning R..