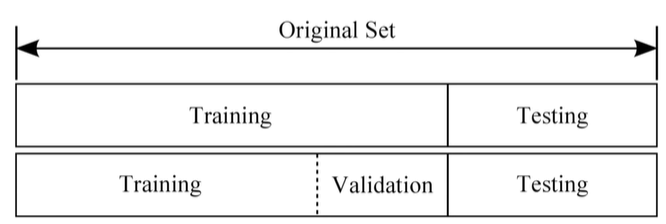
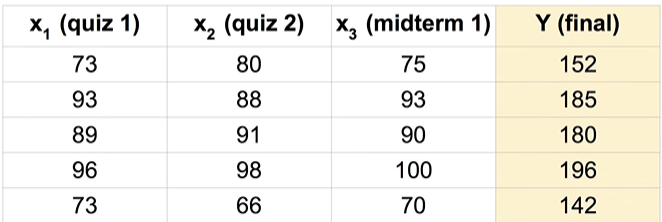
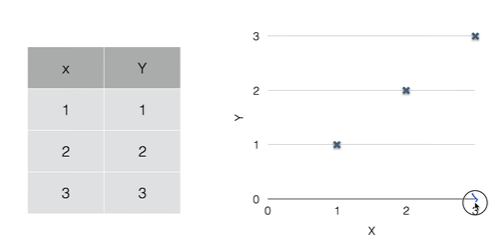
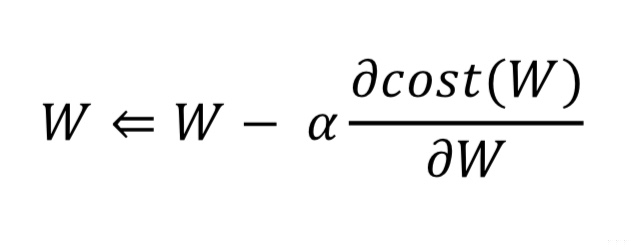머신러닝에서 딥러닝으로 발전한 까닭이 존재한다. 머신러닝은 training set에 대해 사람이 feature를 추출하여 추출된 feature를 바탕으로 각 모델들이 학습하였다. 하지만, 데이터에는 사람이 발견할 수 없는 많은 요소들이 존재한다. 사람이 feature를 추출하고 학습시킨 모델은 일정 양 이상의 training set이 들어오면 정확도가 더 이상 높아지지 않는 문제점이 발생하는 것이다. 따라서 사람이 feature를 추출하는 것이 아닌, feature를 추출하는 일련의 과정마저 모델에게 맡기는 것이다. 새의 사진을 넣고 이러한 생김새를 가진 모든 사진을 새라고 명명하도록 각각의 데이터에 label만 붙여주는 것이다. 이러한 방식을 사용하면 정확도가 더욱 높아질 수 있다는 장점이 있으며 이와..