Semantic Analysis
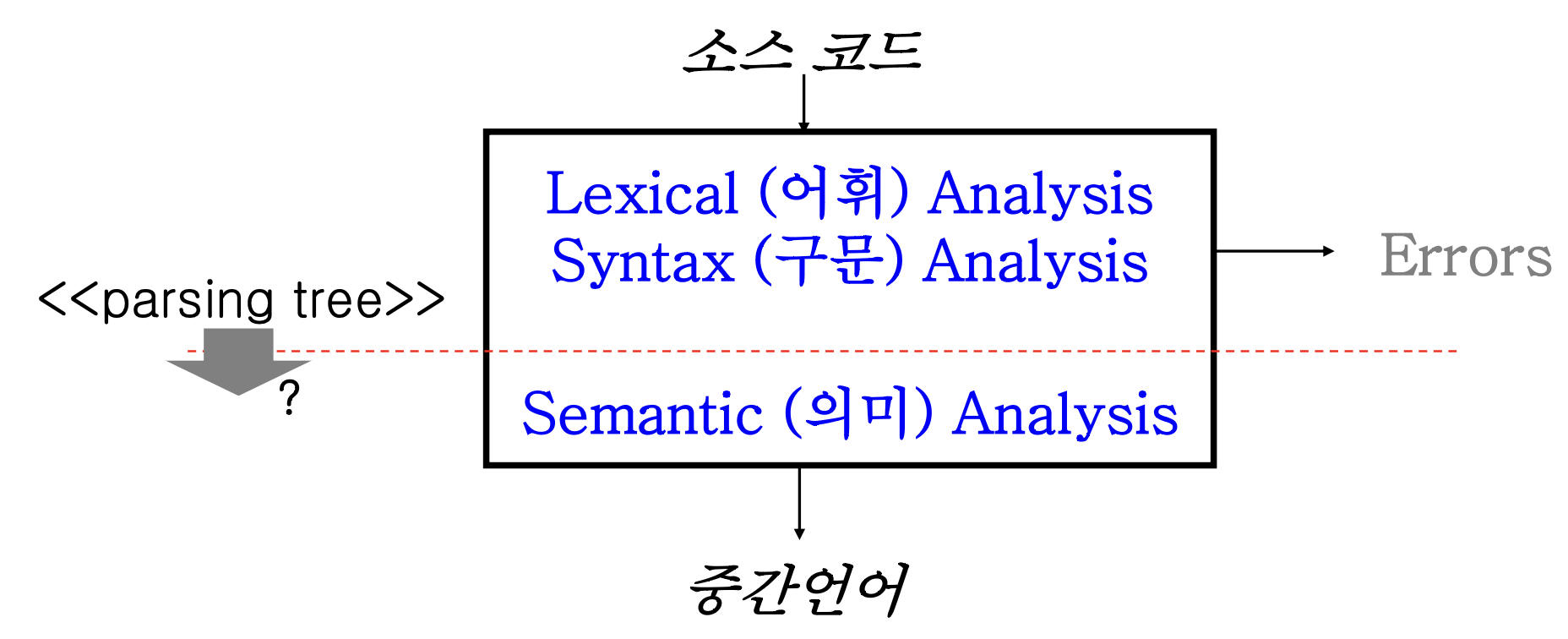
우리는 지금까지 어휘 분석과 구문 분석의 방법에 대해 학습했다.
이제 그 다음 단계인 의미 분석에 대해 학습해야 하는데, 구문 분석한 결과인 parsing tree를 통해 바로 의미를 분석하는 것일까?
사실 파싱 트리를 통해 바로 의미 분석을 해도 되고, 여러 가지 처리 후 의미 분석 단계로 넘어갈 수 있다.
구문 분석에서 의미 분석 단계로 넘어갈 때 필요한 두 가지 도구를 소개하겠다.
- Syntax-Directed Definition/Translation(SDD/SDT)
- Abstract Syntax Tree(AST)
이번 포스트에서는 SDD만 설명하고 마치도록 하고, 이어지는 포스트에서 AST에 대해 설명하겠다.
Syntax-Directed Definition(SDD)
SDD는 파싱 단계에서 의미있는 일을 하는데, 파싱 되는 부분이 match된다고 보고,
여러 다양한 일을 할 수 있도록 reduce 될 때 production마다 '할 일'을 붙여 주는 것이다.
이때, 이 할 일을 semantic action이라고 한다.
파서 생성기에서 주로 사용되는데, 생성된 파서에 삽입될 semantic action을 사용자가 직접 정의할 수도 있다. YACC에서 시작되었으며 가장 많이 쓰인다.
Semantic Action
Action
이 action은 규칙이 reduce되거나, 유도될 때의 일을 말하는데,
이러한 일을 할 때에는 결과값이나 인자값을 저장할 수 있는 메모리가 필요하다.
생성 규칙의 lhs(left-hand side)에 작은 메모리 공간이 있는데 이에 해당 값을 저장한다.
"E -> E + E"라는 생성규칙이 있을 때 우리는 생성 규칙에 존재하는 E를 구분해야 한다.
각 E를 구분해야 action code를 쓸 수 있기 때문이다.
- Yacc/Bison에서는 $$, $1, $2, ...
- ex) expr: expr PLUS expr { $$ = $1 + $3; }
이때, '+'에도 $2라는 이름을 지어주는데, 토큰도 값을 가질 수 있고, 메모리 공간이 필요하기 때문이다.
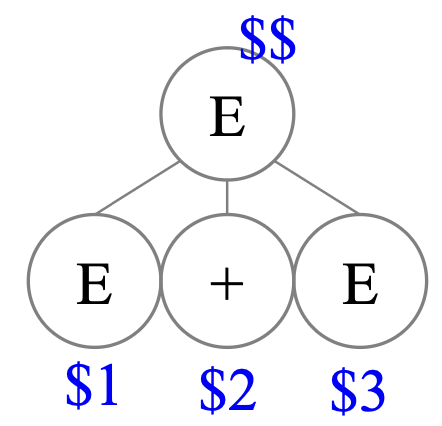
이때, 유도된 E는 보통 $$로 표기가 되는데, 만약 $1이 어디에서 유도된 결과값이라면
해당 유도를 진행할 때 $1은 $$가 된다. 즉 scope에 따라 가리키는 변수가 다르다.
- ANTLR에서는 $<name>
- ex) expr: unary_expr { $expr = $unary_expr; }
이때, nonterminal의 이름을 그대로 사용한다.
parse tree가 다 만들어진 이후 노드를 순회하며 각 노드의 action을 수행한다.
이때, 트리를 만드는 중에 action을 수행할 수도 있으며 각 방법은 아래와 같다.
- LR: bottom-up으로 빌드하며 수행한다.
- LL: recusive decent parser를 상상하며 각 노드에서 return할 때 action을 수행한다.
YACC의 SSD로 계산기 만들기

위 경우 NUM으로 유도되는 경우 lexer에서 그 값 그대로 expr로 가져온다.
또한 LPAR expr RPAR에서 LPAR과 RPAR은 단지 괄호이므로 의미없는 값이기 때문에
값을 가지지 않고 유의미한 expr만 값을 갖는다.
(파스트리에서 우선순위가 반영되므로 괄호로 우선순위를 명시할 필요가 없다.)
위와 같은 SDD가 존재한다고 했을 때, 한 노드마다 실제값이나 타입 등 여러 가지를 저장할 수 있다. 따라서 각 노드가 가지는 값을 아래 사진의 val과 같이 별도의 이름을 사용해서 나타낼 수 있다. 이때 val과 같은 값을 속성(attribute)라고 한다.

이때, expr은 구조체와 같은 형식이며, val 뿐만 아니라 다른 형태의 값도 가질 수 있다.
위와 같이 표기하면, 같은 덧셈이라도 int, float를 따로 구분하여 구현할 필요 없이, 타입 값 등을 이용하여 한 번에 구현할 수 있다.

Lex에서는 위와 같이 yylval의 val로 나타낼 수 있다. yacc에서 구조체의 형식으로 값을 val이라고 표기했다면, lex에서도 해당 이름을 맞춰 주는 것이 좋다.
(이때, atoi는 str을 int로 만들어주는 명령어인데, 입력이 문자열로 들어오기 때문이다.)

YACC에서는 위와 같이 %union을 통해 val이라는 속성을 명시할 수 있다.
각 val에 대하여 terminal은 %token, nonterminal은 %type으로 나타낼 수 있다.

위 사진은 ANTLR를 이용하여 LL 파서를 만들 모습이다. LL의 경우 트리가 완성된 이후 semantic action을 지정해주는데, 왜냐하면 LL은 top-down이기 때문이다. 각 action은 루트부터 트리를 순회하며 시행되는데, 트리를 방문할 때와 해당 노드에서 떠나는 시점이 존재한다.
트리를 방문할 때에는 enterProgram, 떠날 때에는 exitProgram과 같이 ANTLR에서 각 메소드를 제공해준다. 따라서 노드의 방문과 종료 시점에 할 action을 각 메소드의 안에 명시해주면 되는 것이다.
그런데, 보통 action은 bottom-up 방법으로 수행하기 때문에, exit 시점에서 자주 action을 명시한다.
Type Declaration의 예
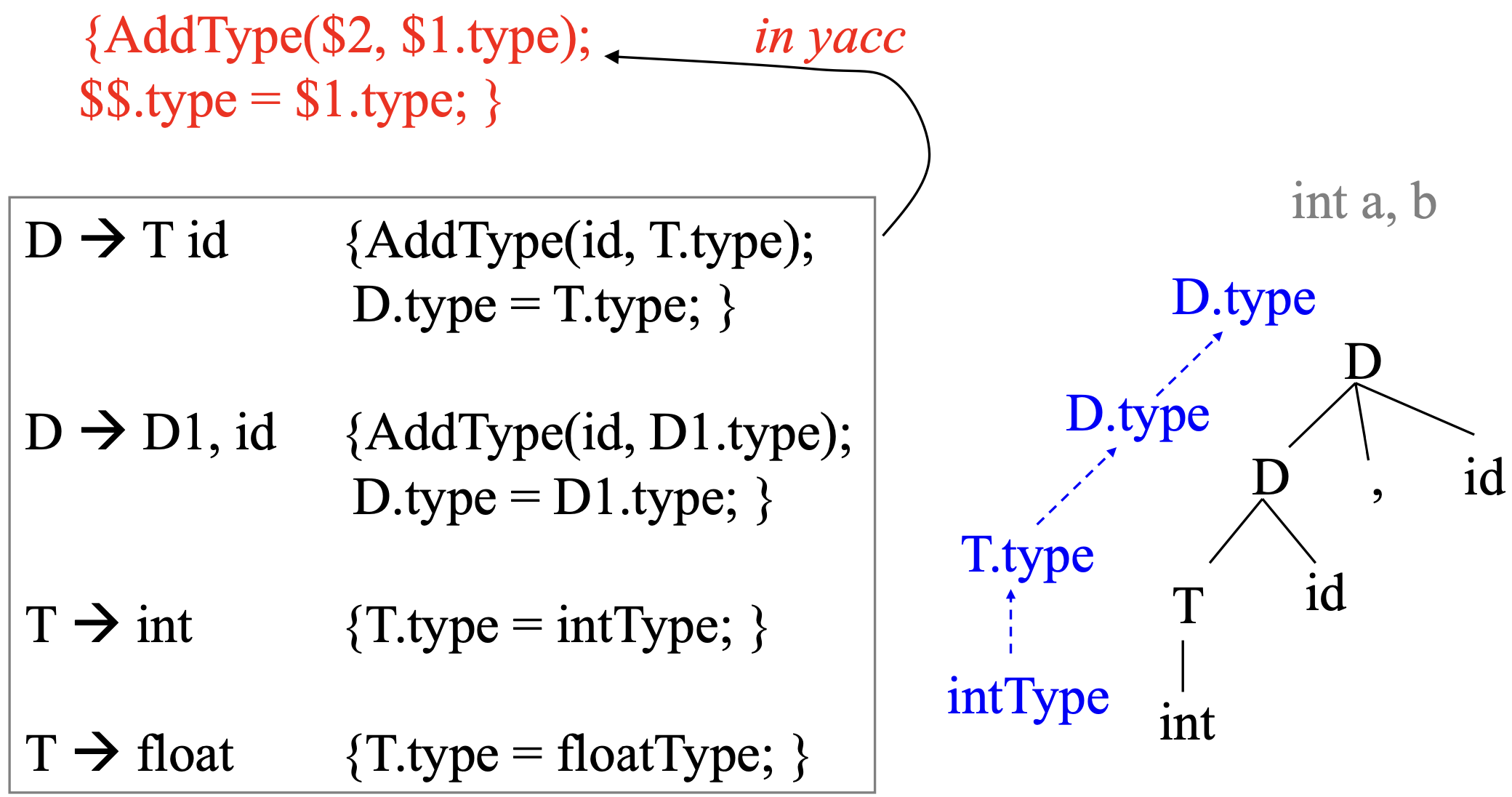
T -> int, T -> float의 경우 상수를 의미하는데, T의 타입에 intType, FloatType을 각각 넣어주겠다는 의미이다.
이후 D -> T id인 경우 id에 Type을 추가해주고, D 즉 $$에 T의 타입을 넣어준다. 이렇게 하는 이유는 바로 아래의 D -> D1, id 부분 때문인데, 콤마(,)를 통해서 변수를 여러 개 선언을 할 때 콤마(,) 앞의 변수와 동일한 타입을 갖게 하기 위함이다.
따라서 각 타입은 오른쪽의 트리 형태를 띠게 되며, 값이 bottom-up 형태로 전파된다.
다른 예
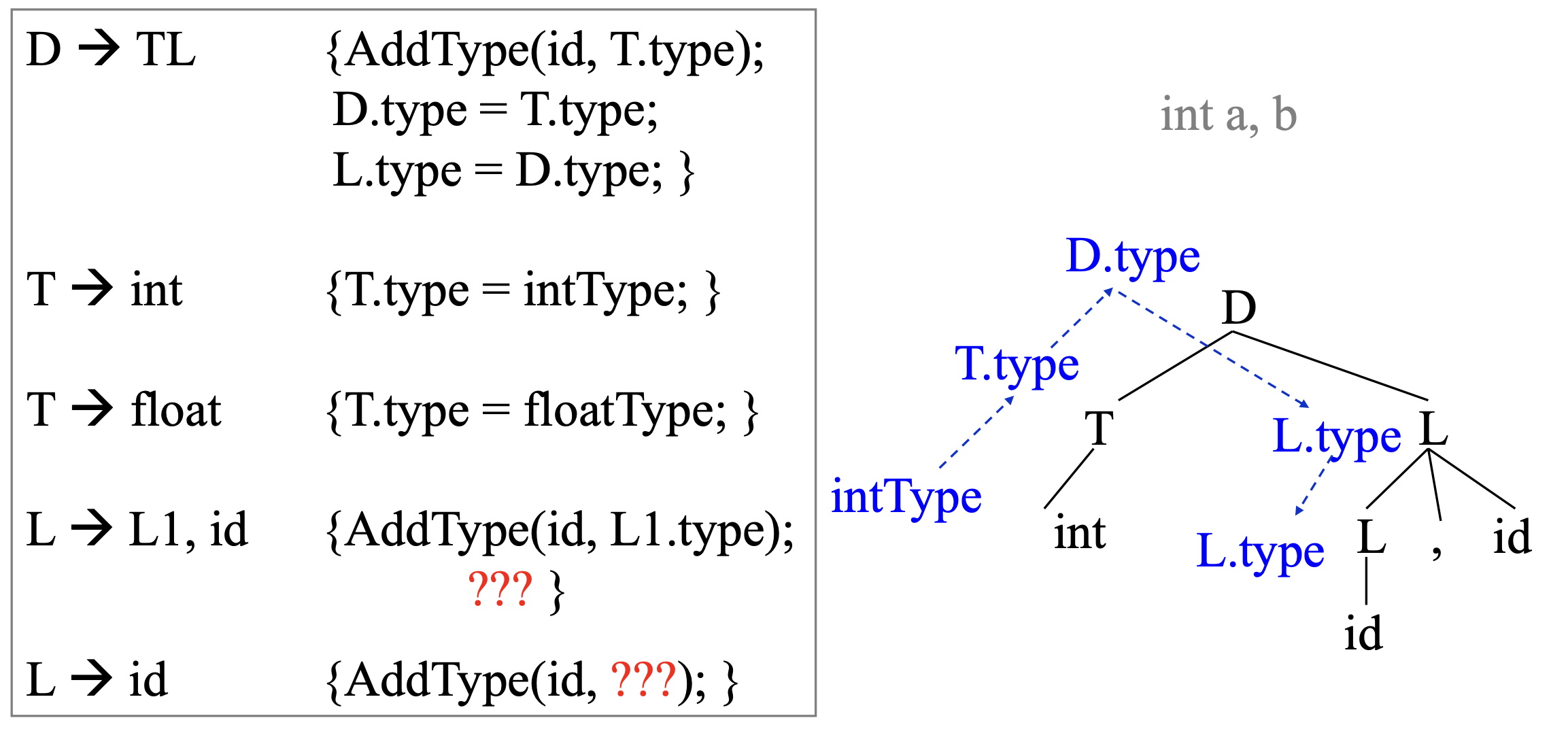
이 예제는 변수 선언 시 변수들을 리스트로 받는 방법이다.
이 방법은 D -> TL에서 L에게 타입을 부여할 때 T의 타입은 쉽게 받아낼 수 있는데, L의 값을 알 수 없다.
그렇다고 L에서 타입을 부여하는 방법은 어떨까.
이 경우 T에서 타입을 모두 받으며 D까지 올라간 후 오른쪽 트리의 점선 모양대로 L의 트리 모양을 따라 다시 내려오게 된다.
따라서 D에서 타입을 얻기 위해 T를 bottom-up 방법으로 값을 가져올 수 있고, L을 Top-down 방법으로 내려가 값을 얻을 수 있다. (bottom-up으로 구할 수는 있지만 쉽지 않아 보인다.)
따라서 두 가지 방법으로 propagation 해야 한다.
속성 (Attributes)의 종류
위와 같은 예시에서 두 가지 방법으로 propagation할 때, 각 요소에 대해 어떻게 값을 유도하는지 정의하기 시작하였다.
A -> XYZ에서
synthesized attr.
- children에 의해 계산된다. (bottom-up)
- terminal은 synthesized attr. 뿐이다.
A.attr = f(X.attr, Y.attr, Z.attr);
이와 같은 구조는 계산기와 같은 구조로 계산이 쉽다는 장점이 있다.
inherited attr.
- parent, sibling에 의해 계산된다.
Y.attr = f(A.attr, X.attr, Z.attr);
이와 같은 구조는 계산을 하기 위해 부모(A.attr)에 갔다가, silbling(X.attr, Z.attr)을 가야 한다.
'Computer Science > 컴파일러개론(Compiler)' 카테고리의 다른 글
| [컴개/CI] Intermediate Representation(IR) (0) | 2023.12.13 |
|---|---|
| [컴개/CI] AST (0) | 2023.12.13 |
| [컴개/CI] Bottom-Up 구문 분석, LALR Parser (0) | 2023.10.22 |
| [컴개/CI] Bottom-Up 구문 분석, 파싱 테이블과 SLR 파서 (1) | 2023.10.22 |
| [컴개/CI] Bottom-Up 구문 분석, LR(0) 파싱 테이블 (1) | 2023.10.22 |