혼잡 제어 개요
혼잡이란 네트워크가 제어할 수 없는 범위 이상의 소스가 전송되는 경우를 말한다.
(이때, 네트워크는 링크, 공유기, 라우터 버퍼 등을 다 포함한다.)
따라서, 혼잡이 발생한 경우 아래와 같은 증상이 나타난다.
1. long delay: 라우터의 버퍼에 해당 패킷이 오래 머물러 발생하는 딜레이
2. packet loss: 라우터의 버퍼가 가득 찬 경우 overflow가 되어 더 이상 수용하지 못 하면 패깃이 손실된다.
따라서 우리는 이러한 혼잡 현상을 제어해야 한다.
이때 우리는 flow control과 혼동할 수 있는데,
flow control은 수신자에 대한 속도 제한으로, 수신자의 상태만 보고 판단한다.
즉, 네트워크를 고려하는 혼잡 제어와 다른 개념이다.
혼잡의 이유와 비용
아래 시나리오를 보자.
1. 라우터는 1개가 존재하고, 라우터의 버퍼 크기는 무한하다.
2. 버퍼의 input과 output은 모두 R개의 생산 능력과 수용력을 가진다.
3. 2개의 flow가 존재하고, 재전송이 필요 없다.
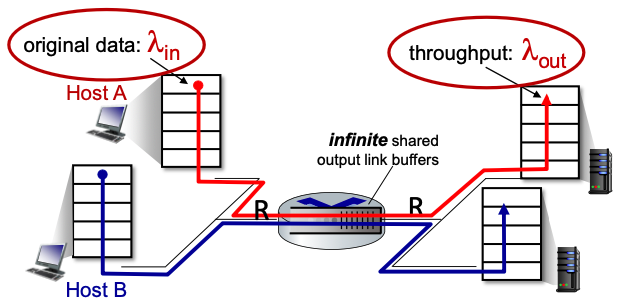
위의 경우 입력과 출력 모두 일정하게 증가하다가 R/2가 되는 시점에서 일정해진다.
왜냐하면, 버퍼의 입출력 가능 개수는 모두 R개이고 flow가 2개이므로
입력을 두 곳에서 받고, 출력은 두 곳으로 나누어 주기 때문이다.
또한, 입력의 개수가 R/2와 가까워질수록 기하급수적으로 딜레이가 커진다.
이때 버퍼의 크기가 무한이므로 packet 손실은 발생하지 않는다.
즉, 아래와 같은 그래프를 그리게 된다.
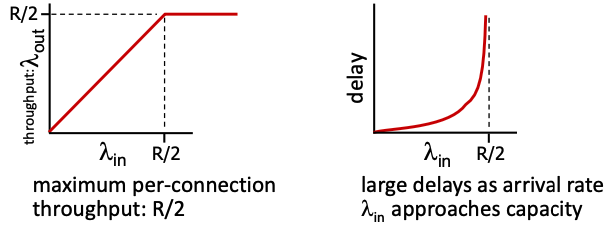
이 시나리오에서는 버퍼의 크기가 무한하지만, 실제로 존재하는 거의 모든 버퍼는 용량이 제한된다.
용량이 제한되는 경우 패킷이 손실되며 손실된 패킷을 재전송하면서
전송하는 패킷의 개수가 증가하는 악순환이 발생한다.
인터넷에서의 혼잡 처리: 탐지, 제어
모든 호스트들은 자기가 더 많은 패킷을 보내고 받으려고 한다.
이때 혼잡을 제어하는 것은, 소스를 공평하게 분배하는 것이다.
즉, 소스가 공평하게 분배되지 않으면 혼잡이 발생한다고 할 수 있다.
TCP 프로토콜의 핵심 기능이 바로 혼잡 제어 기능이다.
컴퓨터 커널 안 TCP 프로토콜이 구현되어 있고,
프로토콜 안에 혼잡 제어기능이 구현되어 있다.
혼잡 탐지
그렇다면 네트워크가 혼잡한지 어떻게 판단할 수 있을까?
보통은 packet loss 신호를 통해 탐지한다.
packet loss 신호를 탐지하는 방법은 크게 두 가지가 있다.
1. 타이머가 time out이 발생하는 경우
2. ACK가 중복되어 들어오는 경우
혼잡 제어
따라서 혼잡이 발생하면 우리는 혼잡을 제어해야 할 필요가 있다.
우리는 TCP 송신자가 보내는 패킷의 양을 줄이는 방법으로 혼잡을 제어한다.
slow start와 AIMD 방식, 두 가지의 단계를 쓸 수 있다.
이 방법은 뒤에서 자세히 언급하겠다.
위의 방법을 구현한 알고리즘은
TCP Tahoe(호수의 이름에서 따왔다.)
TCP Reno, TCP NewReno, TCP Cubic, BBR이 있으며
현재까지도 해당 알고리즘을 사용하고 있다.
혼잡 제어 구현 이유
원래 처음에 만들어진 네트워크는 혼잡 제어 기능이 없었다.
1986년 NSFNET이라는 네트워크 망이 존재하는데,
해당 네트워크가 혼잡으로 인해 32kbits/s였던 출력량이
40bits/s로 줄어드는 상황이 발생하였다.
위의 사건으로 혼잡 제어에 대한 필요성을 느낀
Van Jacobson, Sally Floyds가 1987년에서 1988년 동안
TCP에 재전송 및 혼잡 제어 기능을 만들었다.
본래 TCP는 라우터로부터 신호를 받지 않았다.
따라서 TCP는 수신자의 ACK 정보를 통해 혼잡도를 파악해야 한다.
하지만 최근에 라우터로부터 신호를 받는 기능이 도입되었다.
TCP Timeline
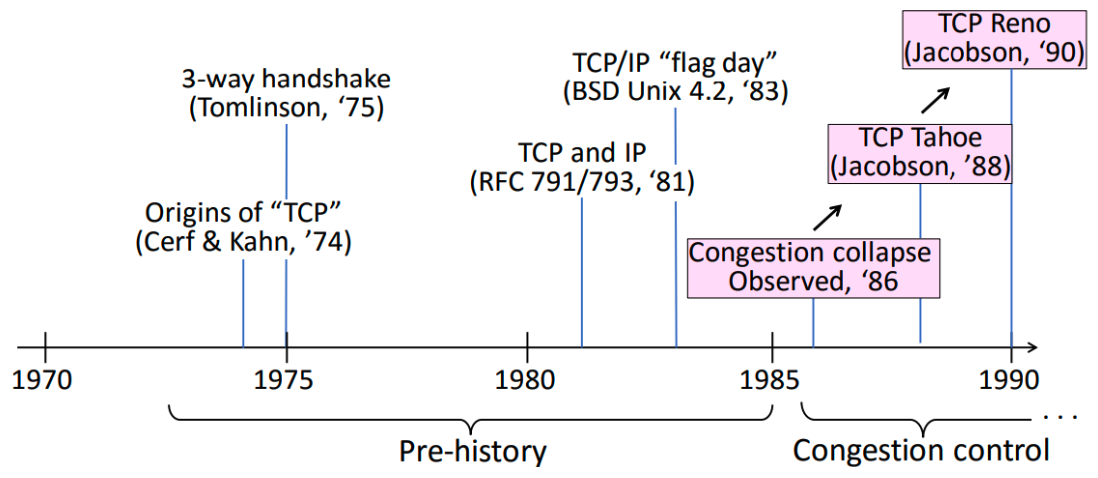
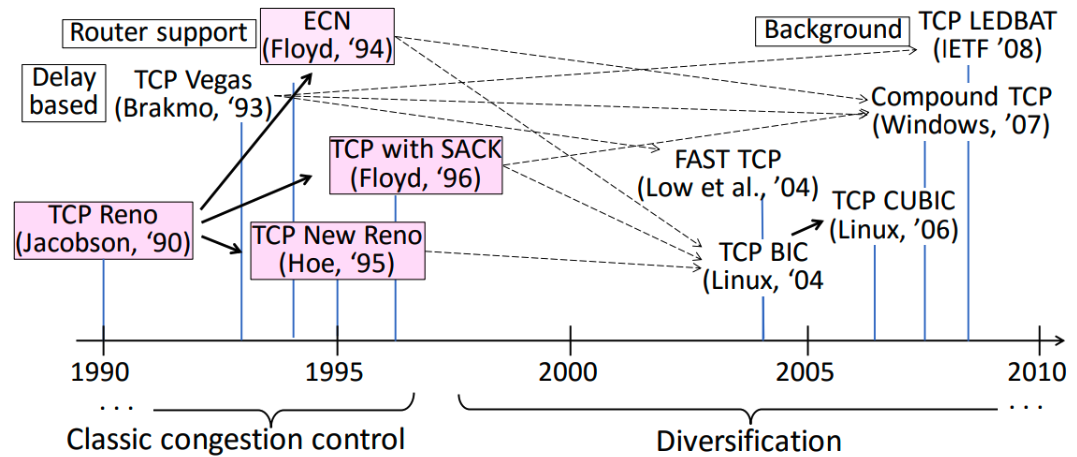
위 사진은 TCP의 발전 과정을 타임라인으로 나타낸 것이다.
TCP Reno가 90년대부터 20년 가까이 사용되었으며,
현재는 안드로이드, ios, 윈도우 등이 TCP CUBIC을 사용하고 있다.
앞서 라우터는 TCP에 아무런 정보를 줄 수 없다고 하였다.
1994년 만들어진 ECN에서 라우터로부터 혼잡함을 알리는 기능이 도입되었지만,
이러한 기능은 모든 라우터에서 지원되는 것이 아니다.
1996년의 TCP with SACK는 우리가 알고 있는 selective ACK이다.
AIMD
AIMD는 Additive Increase Multicative Decrease의 약어이다.
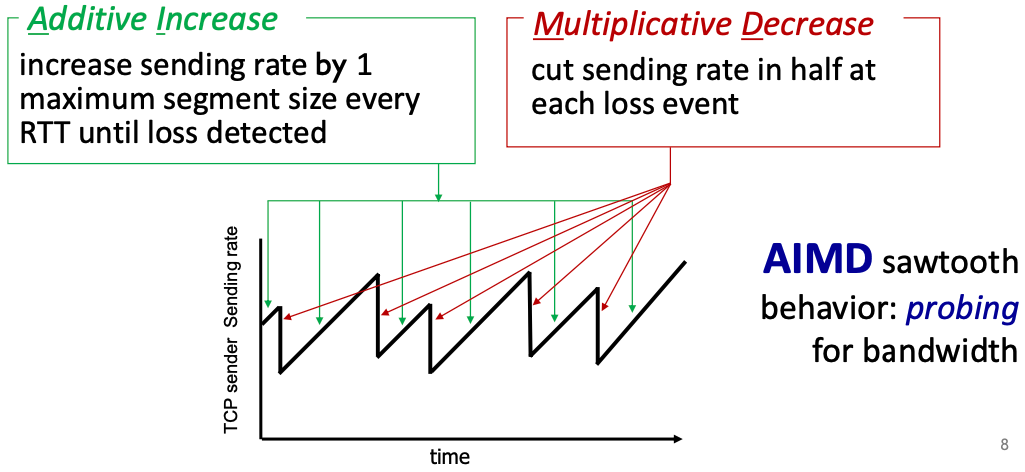
AIMD 알고리즘을 사용하여 송신 시 전송율을 지그재그로 왔다갔다한다.
AIMD알고리즘이 패킷 손실을 감지할 때까지 전송하는 패킷을 늘렸다가,
패킷 손실을 감지했을 때 전송하는 패킷을 줄이기 때문이다.
- additive increase
송신의 window size를 패킷 손실을 감지할 때까지 매 RTT마다
1 MSS(maximum segment size)씩 증가시킨다.
- multiplicative decrease
패킷의 손실을 감지할 때 송신의 window size를 절반씩 감소한다.
이러한 AIMD 알고리즘을 사용하여 구현해낸 것이 혼잡 제어 기능이다.
즉, 패킷 손실 발생 == 혼잡 발생인 것이다.
이때 패킷의 손실을 감지하는 방법은
초창기 TCP Tahoe는 타이머의 time out으로만 감지를 했지만,
이후 등장한 Reno와 같은 혼잡 제어 기능은 중복된 ACK가 3번 이상 반복되면 손실로 판단하는 기능을 추가하였다.
데이터를 전송할 때 각 호스트는 다른 컴퓨터가 데이터를 전송하는지,
트래픽이 혼잡한지 등을 모른 채로 데이터를 전송한다.
또한, 다른 컴퓨터에 대해 비동기적으로 데이터를 전송하므로
각 컴퓨터는 독립적으로 실행(분산)되어야 하므로 AIMD 알고리즘을 사용한다.
AIMD 알고리즘을 사용하면 네트워크 전반의 혼잡도를 최적화해주므로
바람직한 안전성을 얻을 수 있기 때문이다.
TCP congestion control
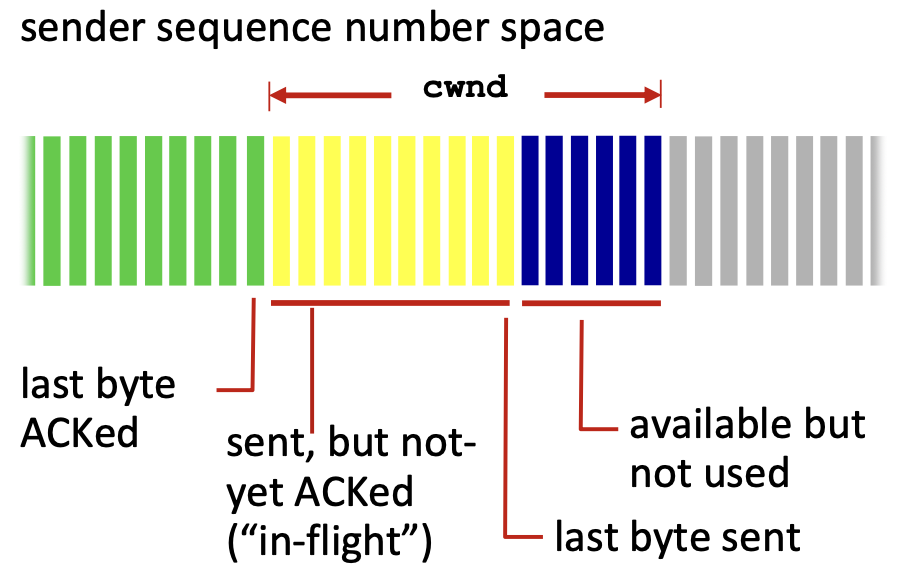
위 사진은 cwnd로 초록색은 이미 전송이 완료된 패킷,
노란색은 전송하였지만 ACK 미수신한 패킷,
남색은 윈도우 안에 들어와 있지만 미송신한 패킷,
회색은 아무것도 아닌 패킷을 의미한다.
이때, cwnd는 congestion window로 커널 안에 설정되어 있는 변수이다.
현재 네트워크에서 허용되는 최대의 데이터 양으로 현재 네트워크의 상황에 맞게
동적으로 조절되어 전송되는 데이터의 양을 제어하는 역할을 한다.
즉, cwnd는 송신자 측에서 혼잡을 제어하기 위해 구현된 부분이다.
따라서 전송되는 데이터는 아래의 식을 만족해야 한다.

위의 식을 간단하게 해석하자면, 송신자의 ack 미수신 데이터의 양은 cwnd를 초과할 수 없다는 의미이다.
TCP는 바이트 단위로 데이터를 전송하고,
데이터 전송 시 송신자의 메모리를 사용하다가 버퍼를 통해 순서대로 전송한다.
TCP에서의 전송 동작은 cwnd만큼의 바이트를 전송한 후 ACKS를 RTT 시간만큼 대기한 후에 바이트를 더 전송한다.
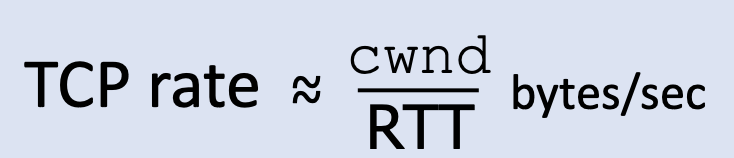
따라서 TCP에서의 전송 속도는 위와 같이 생각할 수 있다.
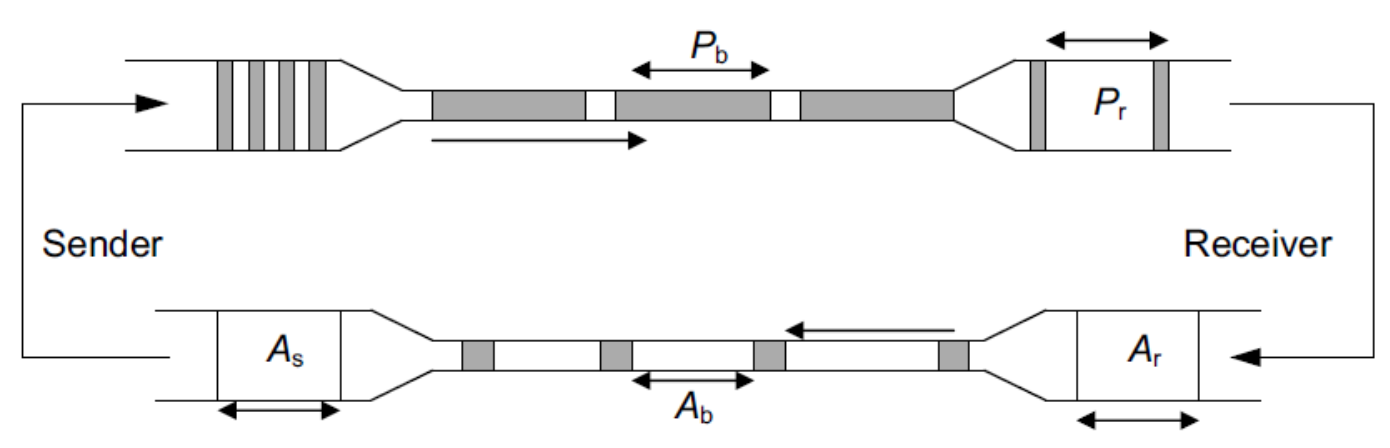
송수신 윈도우의 크기는 보통 cwnd이지만 사실 awnd(수신자의 윈도우 크기)와의 최소값으로 결정된다.
TCP 헤더에 리시버 윈도우 크기가 명시되어 있는데 해당 값이 awnd이고, 이 값들을 통해 흐름을 제어할 수 있다.
TCP에서 혼잡 제어 알고리즘은 아래와 같이 3가지가 존재한다.
1. slow start
2. congestion avoiance
3. fast recovery
TCP Slow Start
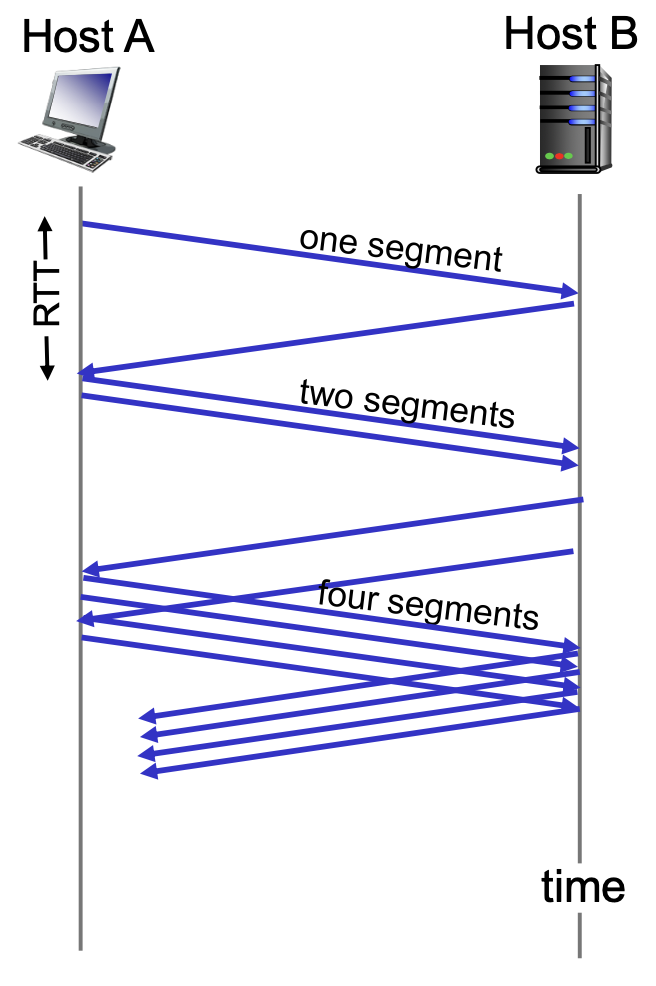
TCP를 통해 데이터를 전송할 때 slow start라는 방법을 사용한다.
이는 cwnd를 1, 2, 4, 8과 같이 지수함수적으로 threshold에 도달하거나 패킷 손실이 발생할 때까지 증가시키는 것을 말한다.
즉, 한 번에 많이 전송하는 것이 아니라 1부터 시작하여 천천히 전송하는 것이다.
초기 cwnd의 값은 1MSS이고 이후 지수함수적으로 증가시킨다.
slow start는 아래와 같은 상황일 때 발생한다.
- TCP 연결이 새롭게 생성되었을 때
- 타이머(timeout)를 통해 패킷 손실이 감지되었을 때
(중복된 ack 탐지로 인한 재전송은 해당하지 않는다.)
RFC5681에서는 1부터 시작하여 지수함수적으로 증가한다.
하지만 최근에는 1부터 시작하여 증가하는 것이 굉장히 느리다.
왜냐하면, 과거에는 email과 같은 큰 크기의 파일을 주로 전송하였다.
하지만 최근에는 웹 사용이 증가하면서 웹 페이지를 로드할 때 순간적으로 작은 파일들을 빠르고 많이 전송해야 하기 때문이다.
따라서 RFC6938에서는 slow start를 10부터 시작하라고 명시하였다.
slow start는 무한하게 지수함수적으로 증가하지 않는다.
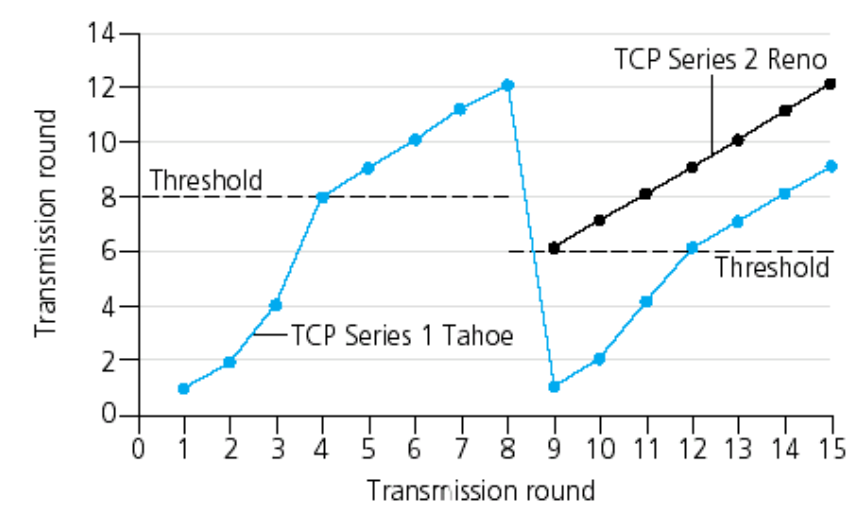
위 사진의 그래프를 보면 Threshold 시점 이후부터 1씩 천천히 증가하고 있는 것을 확인할 수 있다.
Threshold는 혼잡을 회피하기 위한 방법 중 하나로 cwnd가 timeout 되기 전의 1/2값으로 설정한다.
이후 지수함수적으로 증가하다가 Threshold값을 만나면 혼잡 회피 상태가 되어 cwnd가 선형적으로 증가한다. Threshold는 계속해서 재조정되고 변화한다.
이때, Tahoe는 1부터 다시 시작하고, Reno는 절반의 값(임계점)으로 가 선형적으로 증가하고 있음을 확인할 수 있다.
Tahoe
타임아웃이나 중복된 ack로 패킷의 손실이 감지되면 cwnd의 값을 1MSS로 줄이는 slow start를 실행한다.
Reno
타임아웃이나 중복된 ack를 통해 패킷의 손실이 감지되면, cwnd의 값을 절반으로 줄인다.
이때, Reno는 윈도우 크기가 작아지면 전송 속도도 느려지기 때문에 빠른 회복을 진행한다.
빠른 회복(fast recovery)의 방법은 아래와 같다.
- cwnd를 절반으로 줄인 값에 3을 더하기.
(3을 더하는 이유는 중복된 ack가 3개가 왔을 때, 기대 중인 세그먼트가 아닌 이후의 3개의 세그먼트는 잘 도착했다는 의미이기 때문에 해당 ack 개수만큼 더해준다. 이후 드랍된 패킷에 대한 ack를 수신하면 cwnd를 threshold값으로 바꾸고(부풀려진 cwnd 축소) 충돌회피 상태로 향한다?)
- 중복된 ACK가 추가로 수신되면 중복 ACK마다 1MSS씩 증가하기
TCP congestion control 상태도
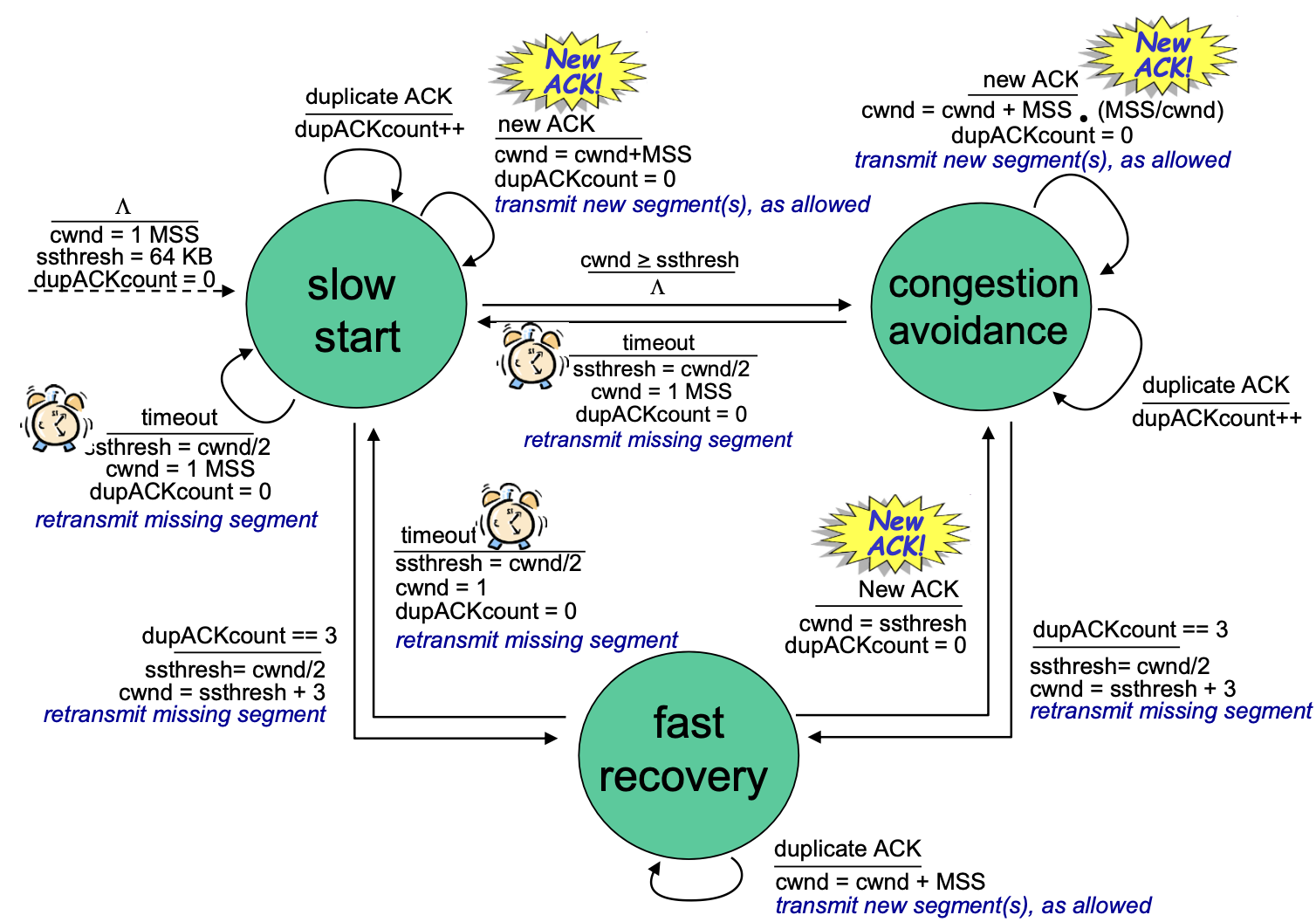
TCP에서의 혼잡 제어는 세 가지의 상태로 나뉜다
slow start
- enter
fast recovery으로부터 또는 slow start, congestion avoidance 상태(모든 상태)에서 timeout이 발생한 경우 threshold값을 1/2로 설정한 후 slow start 상태에 들어오게 된다. TCP 연결이 시작됐을 때에는 threshold값을 64KB로 한다.
위 경우 모두 cwnd를 1 MSS로 설정하고 dupACKcount 변수의 값을 0으로 세팅한다.
- ACK 수신
중복된 ack가 수신되면 dupACKcount 변수에 +1을 한다.
일반적인 ack가 수신되면 ack를 하나 수신할 때마다 cwnd의 값은 이전의 cwnd에 MSS를 더한 값으로 바꾸어 준다. (cwnd = cwnd + MSS) 이때 여러 개의 세그먼트를 송신하기 때문에 모든 세그먼트에 대한 ack를 수신한다면 cwnd의 값은 2배가 되는 것이 맞다.
congestion avoidance
- enter
slow start나 fast recovery 상태에서 cwnd의 크기가 threshold의 크기와 동일할 때 congestion avoidance 상태로 들어오게 된다.
- ACK 수신
중복된 ack가 수신되면 dupACKcount 변수에 +1을 한다.
일반적인 ack가 수신되면 ack를 하나 수신할 때마다 cwnd의 값은 이전의 cwnd값에 1/cwnd(= MSS/cwnd)의 값을 더해준다. (cwnd = cwnd + MSS/cwnd) 마찬가지로 파이프 라이닝을 통해 여러 개의 세그먼트를 전송하므로 모든 세그먼트에 대한 ack를 수신한다면 cwnd의 값은 1씩 증가하게 된다.
fast recovery
- enter
slow start, congestion avoidance 상태에서 중복된 ack가 3번 발생하면 패킷이 손실되었다고 판단하여 fast recovery 상태로 들어오게 된다.
- ACK 수신
일반적인 ack를 수신한 경우 cwnd를 threshold 값으로 설정하고(cwnd = threshold) 충돌 회피 상태로 향한다. dupACKcount 변수는 0으로 초기화한다.
중복된 ACK를 수신하는 경우 ack를 하나 수신할 때마다 cwnd의 값은 이전의 cwnd에 MSS를 더한 값으로 바꾸어 준다. (cwnd = cwnd + MSS) 이때 여러 개의 세그먼트를 송신하기 때문에 모든 세그먼트에 대한 ack를 수신한다면 cwnd의 값은 2배가 된다.
Standard TCP
RFC5681에 명시되어 있으며 Slow start와 congestion avoidance가 구현되어 있다.

이때 SMSS는 sender maximum segment size의 약어로 byte단위이다.
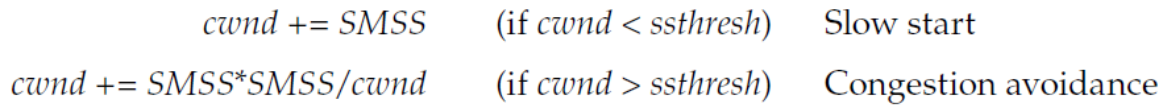
Evolution of TCP
RFC3782에 명시되어 있는 NewReno는 Reno에서 발전된 형태이다.
NewReno는 여러 개의 중복 ack를 수신하였을 때, 해당 패킷만이 손실된 것으로 판단하고 해당 패킷만 빠르게 재전송하며 cwnd를 선형적으로 증가시킨다.
TCP in High-Speed Enviroments
최근 인터넷 환경에서의 속도가 굉장히 빨라졌다.
속도가 10Gbps인 환경에서 1500B인 패킷을 전송한다고 가정했을 때, 10Gbps인 대역폭을 모두 사용하려면 송신자의 윈도우의 크기는 굉장히 커져야 하고, 해당 윈도우에 1500B인 패킷을 채우기 위해 수십 개의 패킷을 윈도우에 넣어야 한다. 이때, 윈도우에 넣는 과정에서 혼잡이 발생한다.
이때, 혼잡을 감지해 윈도우의 크기를 1로 설정한다. 2000개씩 전송하던 데이터가 slow start로 인해 cwnd를 1로 설정된 상황에서 RTT마저 길다면 ack 수신에 오랜 시간이 걸리므로 윈도우 복구에 오랜 시간이 걸린다.
TCP CUBIC
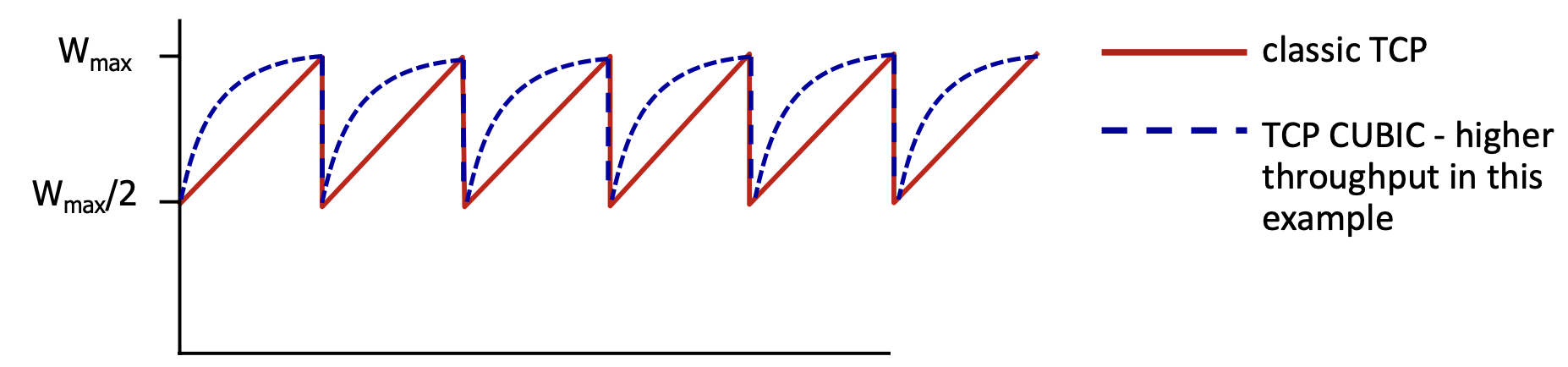
위의 상황으로 인해 등장한 것이 CUBIC이다.
CUBIC는 세 제곱(삼차함수)이라는 의미로 3차 함수의 모양으로 cwnd를 증가시킨다.
고속 환경에서 AIMD로 올리는 것은 굉장히 느리다. 따라서 CUBIC으로 cwnd의 크기를 빠르게 증가시킬 수 있다.
그러나 속도를 증가시킬 때 마찬가지로 무제한적으로 빠르게 증가시키면 안 된다.
따라서 CUBIC도 일정 구간에 도착하면 천천히 증가하도록 한다.
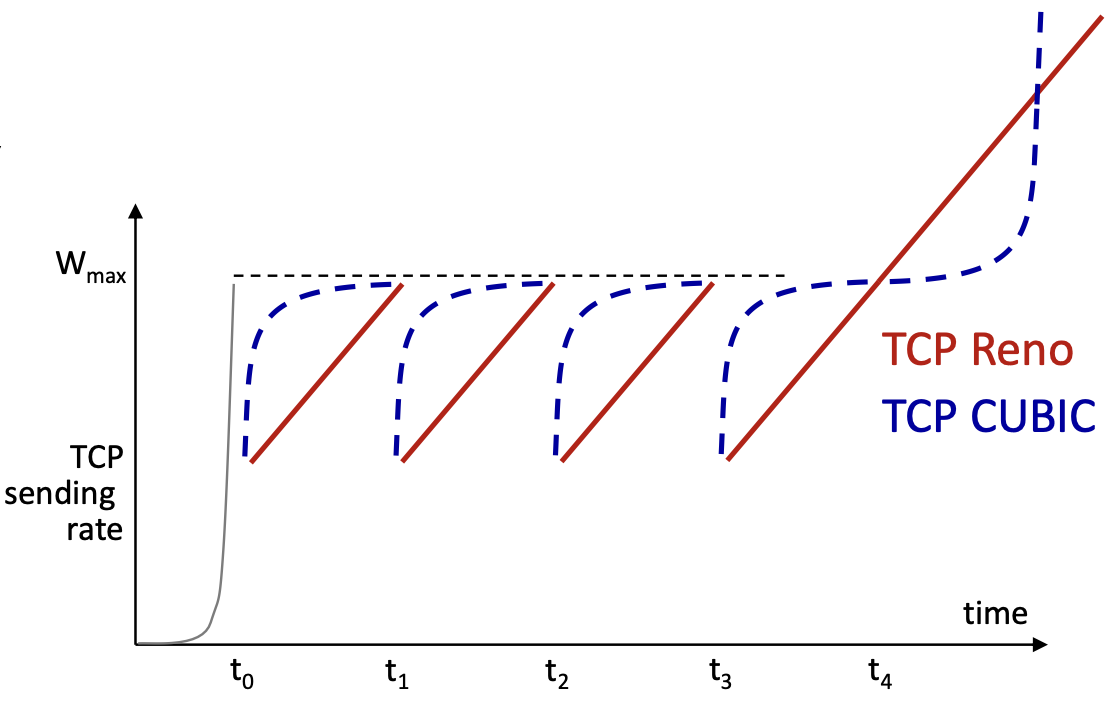
현재 윈도우, 리눅스, 맥 운영체제가 이러한 알고리즘을 사용한다.
이러한 CUBIC 알고리즘은 하상태, 이인종 교수님이 만들었다.
https://github.com/torvalds/linux/blob/master/net/ipv4/tcp_cubic.c
TCP BBR
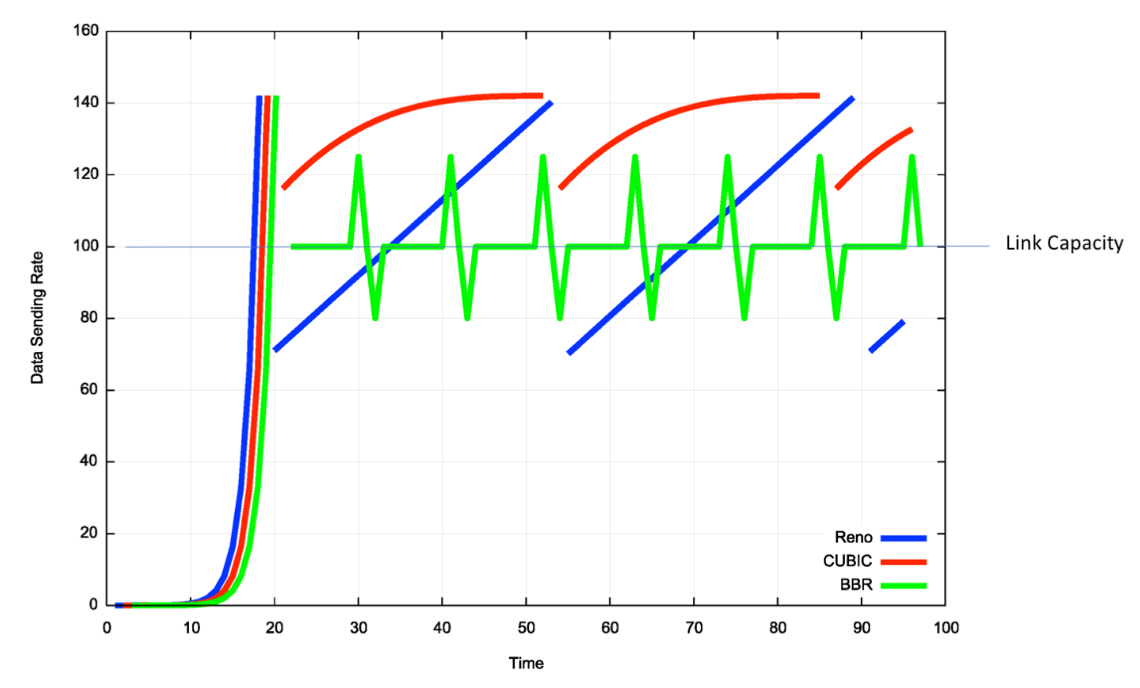
BBR은 Bottleneck Bandwidth and Round-Trip의 약어로 구글이 개발한 혼잡 제어 알고리즘이다.
지금까지의 알고리즘에서 혼잡을 판단할 때에는 패킷 손실로만 혼잡을 판단하였다.
BBR 알고리즘은 혼잡 발생 시 물리적 시간이 증가한다는 점을 이용하여
큐를 통해 혼잡도를 판단하여 대역폭을 조정하는 기능을 추가한 것이다.
TCP 알고리즘의 공정성
TCP 연결은 비동기적인 알고리즘이다.
이때, 10Mbps인 대역폭에 두 개의 연결이 존재할 때 두 개의 연결은 하나의 대역폭을 나누어 사용해야 한다. 하지만 각 연결은 서로의 존재를 모르는 독립적인 상태로 전송되므로 현재 전송하고 있는 데이터에 대해 대역폭을 공정하게 쓰고 있는지 판단할 수 없다.
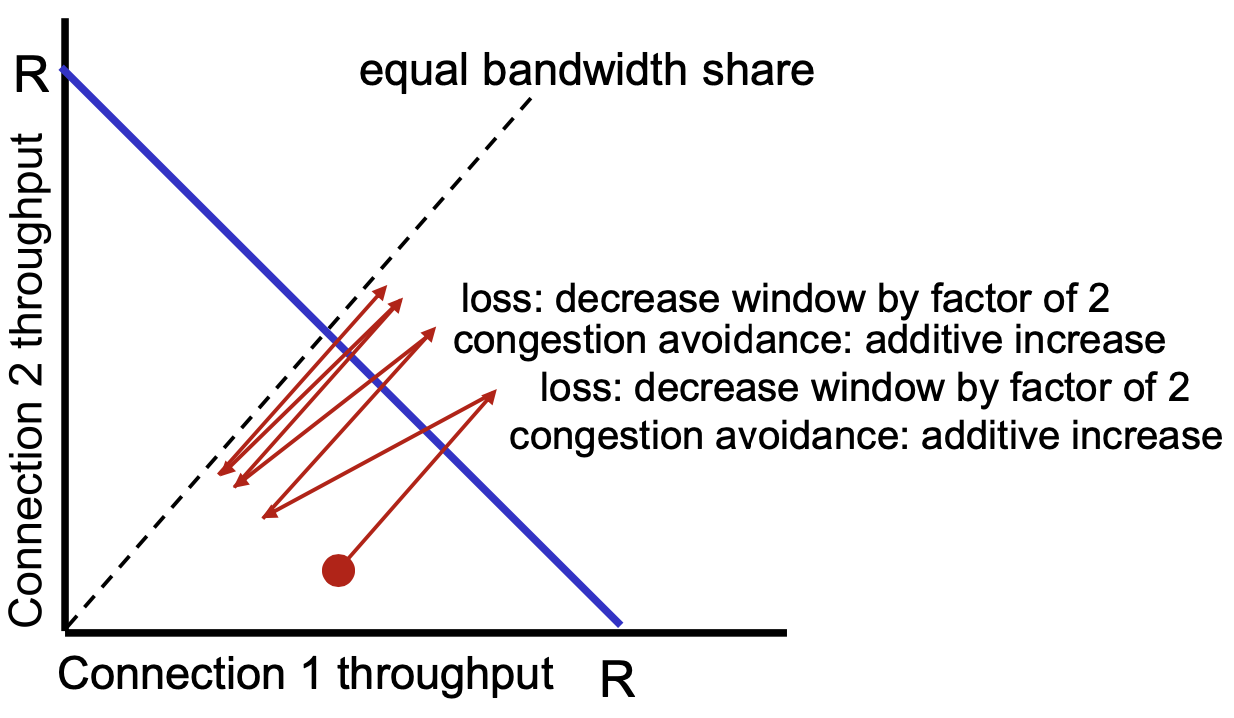
위 그래프는 AIMD로 구현된 두 개의 TCP 연결의 대역폭 사용량을 나타낸 그림이다.
이때, 하나의 연결에 대한 속도가 상승한 후 혼잡이 발생하여 속도가 뚝 떨어지고,
반대의 연결에서도 속도가 상승한 후 혼잡이 발생하여 속도가 뚝 떨어지는 모습을 확인할 수 있다.
이러한 과정이 반복되면서 두 연결의 대역폭 사용량은 점차 가운데로 수렴하게 된다.
TCP Feature

현재는 CUBIC 방식이 대세이다.

출처 및 참고
https://code-lab1.tistory.com/30
https://velog.io/@chullll/%ED%9D%90%EB%A6%84%EC%A0%9C%EC%96%B4-%ED%98%BC%EC%9E%A1%EC%A0%9C%EC%96%B4
https://ai-com.tistory.com/entry/네트워크-TCP-Congestion-Control-2-기본-동작
'Computer Science > 컴퓨터네트워크(ComNet)' 카테고리의 다른 글
| [컴네/CN] 네트워크 레이어의 라우터 큐 (1) | 2023.12.06 |
|---|---|
| [컴네/CN] Network계층의 IP (1) | 2023.12.06 |
| [컴네/CN] Socket Programming (1) | 2023.12.05 |
| [컴네/CN] TCP (0) | 2023.12.04 |
| [컴네/CN] 비동기 프로그래밍 (1) | 2023.12.04 |